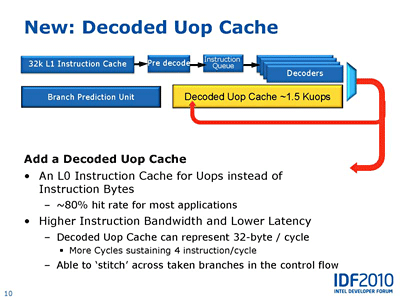
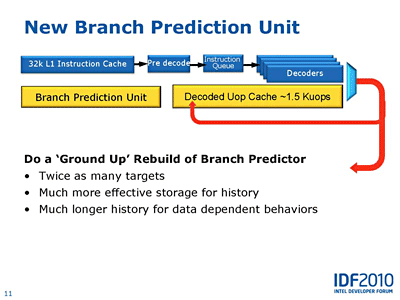
애플 실적 발표 - 한계에 도달한 모바일 사업

미국 애플이 2016년 1월 ~ 3월 실적 발표
(괄호는 전년 동기 대비 비교폭)
총합
매출액 : 505억 5700만 달러 (13% 감소)
순이익 : 105억 1600만 달러 (22% 감소)
지난 2015년 10월~12월 실적 발표 당시 예측된 매출 감소 시작
수 년전부터 매분기 애플 실적을 분석하며 처음으로 타이핑하는 "매출 감소"
각 제품별 판매량
아이폰 : 5119만 3000대 (16% 감소)
아이패드 : 1025만 1000대 (19% 감소)
맥PC : 403만 4000대 (12% 감소)
아이폰 16% 감소 / 프리미엄 스마트폰 시장 한계점
실적 발표가 없어도 예상되는 아이패드 태블릿의 지속적인 판매 감소 / 19% 역성장
맥PC 또한 두 자릿수 역성장
애플의 핵심 3대 디바이스 모두 두 자릿수 역성장
각 제품 및 서비스별 매출액
아이폰 : 328억 5700만 달러 (18% 감소)
아이패드 : 44억 1300만 달러 (19% 감소)
맥PC : 51억 700만 달러 (9% 감소)
서비스 : 59억 9100만 달러 (20% 증가)
기타 : 21억 8900만 달러 (30% 증가)
기타 30% 증가 : 애플워치 순항? = 판매량 확인불가
지역별 매출액
아메리카 : 190억 9600만 달러 (10% 감소)
유럽 : 115억 3500만 달러 (5% 감소)
일본 : 42억 8100만 달러 (24% 증가)
중국 : 124억 8600만 달러 (26% 감소)
아시아 태평양 : 31억 5900만 달러 (25% 감소)
아메리카 / 중국 / 유럽, 3대 대형 시장 모두 역성장
아시아 태평양 또한 25% 감소, 일본만 24% 증가
애플 실적 요약
지속 승승장구했던 애플마저 역성장 시작
한계에 도달한 모바일 시장 및 프리미엄 스마트폰 시장
사업구조 개편 / 신 성장 동력 확보 필요
사물인터넷, 인공지능, 가상현실, 로봇 등 차세대 판도 = 애플이 두각을 나타낼 수 있는 분야는 불명
향후 긍정적인 비전이 보이지 않는 애플
전망이 어려운 혼돈속에 점차 흥미진진해지는 글로벌 IT 마켓
직전 분기(2015년 10월~12월) 실적 확인 - http://raptor-hw.net/xe/hot/121326
랩터 인터내셔널 - http://raptor-hw.net
이하 애플 프레스 릴리스
Apple Reports Second Quarter Results
Capital Return Program Expanding to $250 Billion
CUPERTINO, California — April 26, 2016 — Apple® today announced financial results for its fiscal 2016 second quarter ended March 26, 2016. The Company posted quarterly revenue of $50.6 billion and quarterly net income of $10.5 billion, or $1.90 per diluted share. These results compare to revenue of $58 billion and net income of $13.6 billion, or $2.33 per diluted share, in the year-ago quarter. Gross margin was 39.4 percent compared to 40.8 percent in the year-ago quarter. International sales accounted for 67 percent of the quarter’s revenue.
“Our team executed extremely well in the face of strong macroeconomic headwinds,” said Tim Cook, Apple’s CEO. “We are very happy with the continued strong growth in revenue from Services, thanks to the incredible strength of the Apple ecosystem and our growing base of over one billion active devices.”
The Company also announced that its Board of Directors has authorized an increase of $50 billion to the Company’s program to return capital to shareholders. Under the expanded program, Apple plans to spend a cumulative total of $250 billion of cash by the end of March 2018.
“We generated strong operating cash flow of $11.6 billion and returned $10 billion to shareholders through our capital return program during the March quarter,” said Luca Maestri, Apple’s CFO. “Thanks to the strength of our business results, we are happy to be announcing today a further increase of the program to $250 billion.”
As part of the updated program, the Board has increased its share repurchase authorization to $175 billion from the $140 billion level announced last year. The Company also expects to continue to net-share-settle vesting restricted stock units.
The Board has approved an increase of 10 percent to the Company’s quarterly dividend, and has declared a dividend of $.57 per share, payable on May 12, 2016 to shareholders of record as of the close of business on May 9, 2016.
From the inception of its capital return program in August 2012 through March 2016, Apple has returned over $163 billion to shareholders, including $117 billion in share repurchases.
The Company plans to continue to access the domestic and international debt markets to assist in funding the program. The management team and the Board will continue to review each element of the capital return program regularly and plan to provide an update on the program on an annual basis.
Apple is providing the following guidance for its fiscal 2016 third quarter:
- revenue between $41 billion and $43 billion
- gross margin between 37.5 percent and 38 percent
- operating expenses between $6 billion and $6.1 billion
- other income/(expense) of $300 million
- tax rate of 25.5 percent
Apple will provide live streaming of its Q2 2016 financial results conference call beginning at 2:00 p.m. PDT on April 26, 2016 at www.apple.com/investor/earnings-call/. This webcast will also be available for replay for approximately two weeks thereafter.
This press release contains forward-looking statements including without limitation those about the Company’s estimated revenue, gross margin, operating expenses, other income/(expense), tax rate, and plans for dividends, share repurchases and public debt issuance. These statements involve risks and uncertainties, and actual results may differ. Risks and uncertainties include without limitation the effect of competitive and economic factors, and the Company’s reaction to those factors, on consumer and business buying decisions with respect to the Company’s products; continued competitive pressures in the marketplace; the ability of the Company to deliver to the marketplace and stimulate customer demand for new programs, products, and technological innovations on a timely basis; the effect that product introductions and transitions, changes in product pricing or mix, and/or increases in component costs could have on the Company’s gross margin; the inventory risk associated with the Company’s need to order or commit to order product components in advance of customer orders; the continued availability on acceptable terms, or at all, of certain components and services essential to the Company’s business currently obtained by the Company from sole or limited sources; the effect that the Company’s dependency on manufacturing and logistics services provided by third parties may have on the quality, quantity or cost of products manufactured or services rendered; risks associated with the Company’s international operations; the Company’s reliance on third-party intellectual property and digital content; the potential impact of a finding that the Company has infringed on the intellectual property rights of others; the Company’s dependency on the performance of distributors, carriers and other resellers of the Company’s products; the effect that product and service quality problems could have on the Company’s sales and operating profits; the continued service and availability of key executives and employees; war, terrorism, public health issues, natural disasters, and other circumstances that could disrupt supply, delivery, or demand of products; and unfavorable results of legal proceedings. More information on potential factors that could affect the Company’s financial results is included from time to time in the “Risk Factors” and “Management’s Discussion and Analysis of Financial Condition and Results of Operations” sections of the Company’s public reports filed with the SEC, including the Company’s Form 10-K for the fiscal year ended September 26, 2015, its Form 10-Q for the fiscal quarter ended December 26, 2015, and its Form 10-Q for the fiscal quarter ended March 26, 2016 to be filed with the SEC. The Company assumes no obligation to update any forward-looking statements or information, which speak as of their respective dates.
Apple revolutionized personal technology with the introduction of the Macintosh in 1984. Today, Apple leads the world in innovation with iPhone, iPad, Mac, Apple Watch and Apple TV. Apple’s four software platforms — iOS, OS X, watchOS and tvOS — provide seamless experiences across all Apple devices and empower people with breakthrough services including the App Store, Apple Music, Apple Pay and iCloud. Apple’s 100,000 employees are dedicated to making the best products on earth, and to leaving the world better than we found it.
Press Contact:
Kristin Huguet
Apple
khuguet@apple.com
(408) 974-2414
Investor Relations Contacts:
Nancy Paxton
Apple
paxton1@apple.com
(408) 974-5420
Joan Hoover
Apple
hoover1@apple.com
(408) 974-4570
Apple and the Apple logo are trademarks of Apple. Other company and product names may be trademarks of their respective owners.



'랩터 애널리시스' 카테고리의 다른 글
| HPE 프로라이언트 Gen9 서버부터 NVDIMM 본격 지원 (0) | 2016.04.30 |
|---|---|
| 아마존 웹 서비스, 고속 SSD 기반 EBS 볼륨 제공 (0) | 2016.04.28 |
| 인텔 CPU,메인보드,SSD 종류 및 스펙 (서버/PC/모바일) (0) | 2016.04.25 |
| 비 노이만 아키텍처 시냅스칩(SyNAPSE) - IBM (0) | 2016.04.24 |
| 양자 컴퓨터 CPU 개발 - 큐비트 (0) | 2016.04.24 |