스카이레이크의 저전력 기술 스피드시프트(SpeedShift)
인텔은 IDF15의 테크니컬 세션에서 6세대 Core 프로세서(개발 코드 네임:스카이레이크)의 마이크로 아키텍처에 관한 설명을 진행했다. 그 중 특히 모바일 PC 사용자들이 주목 할 만한 새로운 저전력 기술 "Intel SpeedShift Technology"(이하 SpeedShift)가 소개됐다.
Haswell/Broadwell세대에서는 아이들시(C스테이트)소비 전력 절감
현대의 마이크로 프로세서의 소비 전력을 말할때 CPU가 어떻게 돌아가는지 이해할 필요가 있다. 마이크로 프로세서에는 크게 액티브 모드와 아이들 모드가 있다. OS가 동작하고 있어 CPU가 뭔가 처리되고 있을때 액티브 모드가 된다.
PC/AT호환기의 전력 동작을 규정하고 있는 ACPI(Advanced Configuration and Power Interface)의 규격에서 이 액티브시 상태를 "P스테이트"라고 정의하고 있다. OS나 어플리케이션이 일시 정지(아이들)상태에 있는 모드에서는 C스테이트가 된다. 마이크로 프로세서는 P스테이트(액티브)와 C스테이트(아이들)을 반복하며 필요에 따라 동작함으로써 소비 전력을 최소화하게 된다.
인텔은 4세대 Haswell에서 C스테이트의 전력 절감을 실현하는 개량을 하고 있다. 종래는 C0~C6까지 밖에 없었던 C스테이트를 확장해 C7~C10으로 불리는 더욱 저전력 아이들 스테이트를 추가했다. C7~C10에서는 종래에는 못한 칩셋의 전력 관리를 보다 세세하게 컨트롤 하는 등의 기능이 추가되어 아이들시 소비 전력 절감이 실현됐다. PC가 작동하고 있을때 대부분의 OS는 아이들 상태가 되고 마이크로 프로세서는 C스테이트로 이행하므로 Haswell과 5세대 Broadwell에서는 이전 세대와 비교하여 보다 장시간의 배터리 구동이 실현됐다.
액티브시(P스테이트)전력 절약 관리를 담당했던 것은 15년전에 등장한 SpeedStep
이에 비해 스카이레이크 세대는 Haswell/Broadwell세대에서 실현된 C스테이트의 전력 절약 외에 P스테이트의 전력 절약 확장이 시행된다.
지금까지 인텔의 마이크로 프로세서에서 P스테이트의 전력 절약 관리를 해온 것은 Intel SpeedStep Technology(이하 SpeedStep)이라 불리는 기술이다. SpeedStep은 간단하게 말하면 클럭 주파수와 구동 전압을 동적으로 바꾸면서 소비 전력을 절감하는 기능이다. 마이크로 프로세서의 소비 전력은 클럭 주파수에 비례하고, 구동 전압은 2제곱에 비례적으로 늘어난다. 그래서 클럭 주파수와 구동 전압 양쪽을 내리는 것이 전력을 절감하려면 가장 좋다고 할 수 있다.
그러나 전압을 올리지 않으면 클럭 주파수도 오르지 못하며 성능을 올리면 전력이 늘어날 것이다. 거기서 성능이 필요 없는 상황에서 구동 전압과 클럭 주파수를 낮춰 동작시키고 성능이 필요할때는 구동 전압과 클럭 주파수를 올려 동작시킴으로써 성능과 전력 절약의 균형을 취할 수 있다. 이것이 SpeedStep의 기본적인 생각이다.
1999년에 발표된 최초의 SpeedStep은 AC어댑터의 유무로 상위 클럭/전압, 하위 클럭/전압을 전환하겠다는 단순한 것이었다. 그 후 2001년에 투입된 130nm로 미세화된 Pentium III프로세서(개발 코드 네임:Tualatin)에서는 Enhanced Intel SpeedStep Technology(EIST)로 불리는 진화버전이 투입됐다. EIST에서는 최고와 최저라는 2가지 포인트만 아니라 클럭/전압을 다단계로 전환되게 되고 트리거로 AC어댑터의 유무뿐 만 아니라 CPU에 걸리는 부하에 맞춰 변환이 가능하게 됐다.
기본적으로 그 후 발매된 인텔의 마이크로 프로세서는 EIST가 P스테이트에 있을때 전력 절약 기능으로서 이용되어 왔다. 다만 그 뒤에도 기능의 확장이 이뤄지지 않은 것은 아니다. 구체적으로는 Nehalem세대에서 도입된 Intel Turbo Boost Technology는 일종의 EIST의 확장과 다름없다. Turbo Boost는 시스템이 식어 있고 열 설계에 여유가 있는 상태일때 규정의 가동 보증 주파수를 넘는 클럭 주파수/전압으로 올리는 기능이다. 즉, EIST가 전력 절감을 위한 기술인 반면 Turbo Boost은 그 반대로 성능 향상에 사용한다는 것이다. 그러한 확장은 있었지만 전력 절약 기능이라는 관점에서 생각하면 기본적으로 1999년에 도입된 SpeedStep이 그대로 이용되어 왔다.

마이크로 프로세서에 내장된 PCU에 의해 자동 제어되는 SpeedShift
그런 P스테이트의 전력 절약 기능을 대폭 확장하는 것이 스카이레이크로 투입된 스피드시프트(SpeedShift)다. 종래의 EIST가 OS를 포함한 소프트웨어 측이 제어를 하겠다는 것으로 실현된 반면 스피드시프트는 클럭 주파수/전압의 변동을 하드웨어가 내부 알고리즘에 기초하여 제어한다.
인텔의 마이크로 프로세서는 PCU(Power Control Unit)로 불리는 전원 관리 하드웨어를 갖고 있으며 스카이레이크는 이 PCU가 원래 마련된 알고리즘에 기초하여 자동적으로 CPU의 주파수와 전압을 관리한다. 구체적으로는 최고 주파수(기존 Turbo Boost시 최고 클럭), 가동 보증 주파수(기존의 기준 클럭), 최적 전력 주파수(Pe라고 불리는 자동차 엔진의 가장 연비가 좋은 회전 수 같은 것이라고 생각하면 된다), 최저 주파수 등이 정의되고 그 중간 주파수에 설정할 수도 있다.

스카이레이크의 PCU는 정해진 알고리즘에 기초하여 계산하며 어플리케이션이나 워크 로드를 통한 다른 최적의 전력 주파수를 찾으면서 필요에 응해 최고 주파수로 올리거나 가동 보증 주파수로 설정, 최적 전력 주파수로 설정하는 것을 자동으로 한다. 또한 최저 주파수는 스카이레이크 세대의 경우에는 100MHz다.

이 자동 컨트롤 기능은 OS측에서 오프라인으로 할 수 있다. 그 경우 기존의 SpeedStep과 마찬가지로 OS측에서 CPU부하 등을 체크하면서 주파수의 등락을 요청할 수 있다. 혹은, OS측에서 이 정도의 전력 절약화를 해달라는 등의 리퀘스트를 보내겠다는 구조도 준비되어 있다.
PCU에서 자동 컨트롤을 할 경우의 장점은 기존의 Turbo Boost로 관리된 부분도 포함하여 최저 주파수에서 최고 주파수까지 들어가 조절할 것이다. 이로써 필요에 응한 성능을 향상시킬 수 있으며 OS의 응답성을 개선하거나 최적 전력 주파수 부근에 최대한 접근할 수 있도록 하고, 기존보다 효율적인 전력 관리가 될 것이다.

Windows 10의 장래 업데이트에서 이용 가능하게, Windows 10+스카이레이크에서 새로운 장시간 배터리 구동이 실현된다
이 스피드시프트를 이용하려면 OS측의 실장이 필요하다. 인텔에 따르면 Windows 10의 스피드시프트 구현을 현재 Microsoft와 협력하고 있는 단계다. 가까운 장래에 나올 예정인 Windows 10의 업데이트 등에서 구현된다. 또 리눅스도 현재 리눅스 커뮤니티와 협력하여 개발하고 있다고 밝혔다.
IDF에서 열린 테크니컬 세션에서 벤치마크 결과도 제시하여 WebXPRT15와 TabletMark3 같은 벤치마크 테스트에서 처리 능력은 상승하는데 소비 전력은 떨어진다는 결과가 나온다고 한다.

2-in-1디바이스, 혹은 초박형 노트 PC를 이동형으로 쓰는 사용자에게는 조금이라도 편안하고 오랜 시간 배터리를 사용하고 싶은 희망이 있다. Haswell로 새 C스테이트의 추가 등으로 그 희망은 많이 실현되었다고 말할 수 있지만 스카이레이크는 그에 더해 P스테이트의 새로운 제어 가세로 더욱 장시간 배터리 구동이 실현 될 가능성이 있다. 윈도우10에 대한 구현과 아울러 향후 등장하는 윈도우10 장착 노트북 PC와 2-in-1디바이스 등에 장착되는 것을 기대하고 있다.
출처 - http://pc.watch.impress.co.jp/docs/column/ubiq/20150820_717008.html
'글로벌 IT 뉴스' 카테고리의 다른 글
| 2015년 2분기 글로벌 태블릿 시장 점유율, 시장축소 가속 (0) | 2015.09.16 |
|---|---|
| IoT용 SoC와 3D XPoint 기술의 고속 SSD 옵테인 (0) | 2015.09.16 |
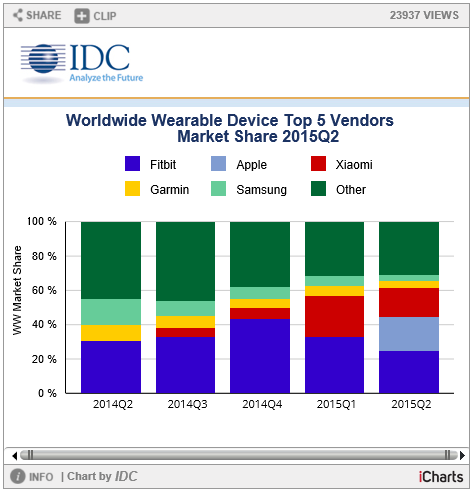
| 세계 웨어러블(스마트워치) 점유율 (0) | 2015.09.15 |
| ASUS, 트라이 밴드 11ac 라우터 RT-AC3200 발매 (0) | 2015.09.15 |
| 미국에서 NFC 결제 서비스 안드로이드 페이 시작 (0) | 2015.09.15 |