인텔은 14nm 기술에 기반한 놀라운 FPGA(Field Programmable Gate Array, FPGA) Stratix 10 GX 10M을 발표했다. 이는 세계에서 가장 큰 FPGA로 이전에 가장 큰 자일링스의 Virtex VU19P FPGA를 제압했다.
Stratix 10 GX 10M은 인텔 자체의 EMIB(Embedded Multi-die Interconnect Bridge)에 의해 연결된 2개의 대형 다이에 1,200만개 이상의 로직 셀이 내장되고 있다. 10M 모델은 EMIB로 연결되는 로직을 위한 2개의 로직 외 최대 4.5Tb/s의 총 대역폭을 갖는 48개의 트랜시버 포함 4개의 추가 다이를 패킹하고 있습니다. 모든 다이 사이의 대역폭은 EMIB의 25,920 연결로 판단 할 때 6.5Tb/s의 내부 다이 대역폭이 존재하므로 구성 요소가 데이터를 전송하기 위한 추가 속도에 부족하지 않을 것이며 또한 2,304개의 사용자 I/O핀이 있으므로 개발 목적으로 많은 포트가 포함된 창의적인 통합 솔루션을 사용할 수 있다.
여러 Redditor의 공동 노력으로 AMD가 곧 출시 할 7nm "Navi 14" GPU를 기반으로 최대 5개의 Radeon RX 5000 시리즈 SKU를 준비하고 있음을 발견했다. 그들은 AMD의 오픈 소스 GPU 드라이버 파일에 수천 줄의 코드를 쏟아 부었다. 그 중에는 2개의 모바일 GPU와 3개의 데스크탑이 있다. "Navi 14" 실리콘은 1,536개의 스트림 프로세서를 구성하고 최대 24개의 RDNA 컴퓨팅 장치를 특징으로 한다. 128비트 대역의 GDDR6 메모리 인터페이스 실리콘을 기반으로 한 가장 높은 모델은 "Navi 14 XTX" 변형이며 이는 상품명 Radeon RX 5500XT.
실리콘에 존재하는 24개의 CU를 모두 최대한 활용하는 점도 주목 할 만하지만 1717MHz로 가장 높은 클럭을 갖고 있다. 다음은 Radeon RX 5500("Navi 14 XT")다. 이 SKU는 2019년 10월 AMD 제품 발표에서 대중화되었다. 칩의 128비트 메모리 인터페이스에 1,408개의 스트림 프로세서와 최대 8GB의 GDDR6 메모리로 작동하는 22개의 컴퓨팅 유닛이 특징이며 클럭은 1670MHz.
다른 SKU는 Radeon RX 5500M("Navi 14 XTM"). RX 5500과 동일한 코어 구성을 갖춘 이 SKU는 클럭 속도가 약간 낮아져 보다 적극적인 전원 관리에 기여하며 클럭은 1448MHz. AMD는 Radeon RX 5300 시리즈인 "Navi 14"를 기반으로 완전히 다른 GPU 세그먼트를 만드는데 관심이 있는 것으로 나타났다. RX 5300 시리즈는 "Navi"를 기반으로 한 AMD의 엔트리 레벨 일 수 있으며 CU 수가 적고 128비트 메모리 버스에 GDDR5 메모리로 더 저렴할 수 있다. 이 라인업에는 피크 클럭이 1448MHz 인 Radeon RX 5300("Navi 14 XL")과 클럭 속도가 느린 모바일 형제 Radeon RX 5300M("Navi 14 XLM")의 두 가지 SKU가 있다.
3분기 총 매출액은 18억 8천만달러, 영업 이익은 1억 8천 8백만 달러, 당기 순이익은 1억 2천만달러를 기록했다. AMD의 Lisa Su는 “7nm Ryzen, Radeon 및 EPYC 프로세서 판매의 첫 번째 분기는 2005년 이후 분기 매출이 가장 높았고, 2012년 이후 분기별 총 수익률이 높았으며 전년 대비 순이익이 크게 증가했다."
2019년 3분기 컴퓨팅 및 그래픽스 부문의 매출 증가로 인해 매출이 전년 대비 9%, 분기 대비 18% 증가한 18억 8천만 달러를 기록했으며 엔터프라이즈, 임베디드 및 세미 커스텀 부문의 매출 감소로 일부 상쇄됐다.
마진은 Ryzen 및 EPYC 프로세서 판매 증가로 인해 전년 대비 3%, 분기별로 2% 증가한 43%를 기록했고, 영업 이익은 전년 1억 5천만 달러에서 1억 8천 8백만 달러로 소폭 증가했다.
컴퓨팅 및 그래픽스 부문은 Ryzen 클라이언트 프로세서 판매 증가로 인해 발생했고, 클라이언트 프로세서 평균 판매 가격(ASP)은 주로 Ryzen 데스크톱 프로세서 판매로 인해 전년 대비 증가했다. GPU ASP는 모바일 판매 비중이 높아 채널 판매 증가로 인해 전년 대비 증가했으며 분기별로는 감소했다.
엔터프라이즈, 임베디드 및 세미 커스텀 부문 매출은 전년 대비 27% 감소한 5억 5천 5백만달러를 기록, 전년 대비 및 분기별 감소는 주로 EPYC 프로세서 판매 증가로 부분적으로 상쇄됐다.
인텔은 현재 생산 설비를 풀가동해도 엄청난 수요를 맞추지 못하고 있는 상황으로써 AMD가 그러한 일부 수요를 대신함으로써 이득을 보고 있는 것으로 나타났다. 그러나 인텔은 향후 생산 능력을 25% 증가시킬 예정으로 이후에는 AMD의 수익에 또 다시 영향을 줄것으로 전망되고 있다.
Top Companies, Worldwide Traditional PC Shipments, Market Share and Year-Over-Year Growth, Third Quarter 2019 (Preliminary results, shipments are in millions of units)
Company
3Q19 Shipments
3Q19 Market Share
3Q18 Shipments
3Q18 Market Share
3Q19/3Q18 Growth
1. Lenovo
17.3
24.6%
16.2
23.6%
7.1%
2. HP Inc.
16.8
23.8%
15.4
22.5%
9.3%
3. Dell Technologies
12.1
17.1%
11.5
16.8%
5.3%
4. Apple
5.0
7.1%
5.3
7.7%
-6.1%
5. Acer Group
4.4
6.3%
4.8
7.0%
-7.2%
Others
14.8
21.1%
15.3
22.4%
-3.2%
Total
70.4
100.0%
68.4
100.0%
3.0%
Source: IDC Quarterly Personal Computing Device Tracker, October 10, 2019
시장조사 기관 IDC(International Data Corporation)에 따르면 데스크톱, 노트북, 워크스테이션으로 구성된 전세계 PC 출하량은 2019년 3분기(3Q19)에 7,420만대에 도달했습니다. 상업 부문의 수요는 미국과 중국 간의 무역 전쟁임에도 시장을 진전시키며 2018년 3/4 분기 동안 선적이 3% 증가하며 2분기 연속 성장을 기록했습니다.
리서치 매니저 지테쉬 우브라니(Jitesh Ubrani)는 “지리적인 관세가 높아지면서 PC 제조업체들은 인텔의 공급 제한에 직면해 프로세스가 조금 더 어려워졌지만 이번 분기에 재고를 추가로 늘리기 시작했습니다. 대부분의 노트북 제조업체들은 이제 대만과 베트남과 같은 아시아의 다른 국가로 생산을 옮길 준비가 되어 있기 때문에 무역 전쟁은 공급망의 변화로 이어지고 있습니다."고 밝혔으며 디바이스 및 디스플레이 리서치 부사장 린 황 (Linn Huang)은 “기업들이 나머지 Windows 10 마이그레이션을 통해 업무를 수행함에 따라 상업적 수요가 가속화 될 것” 이라고 밝혔습니다.
이번 분기에 출하 된 4대의 PC 중 거의 1대는 Lenovo 또는 자회사 중 하나였습니다. 회사가 다시 한번 시장에서 1위를 차지했고, 이 회사의 EMEA 및 일본에서의 강력한 추진은 주목할 만한 상업적 존재를 나타냈습니다.
HP Inc는 분기 동안 1,680만대의 PC가 출하되었으며 상위 5개 회사 중 전년대비 가장 빠른 성장률을 기록했습니다. 특히 이 회사의 노트북 라인업은 전년 대비 10%의 성장률로 전체 노트북의 4%를 능가하여 상당히 강력했습니다.
델 테크놀로지스는 전년 대비 5.3% 성장한 1,110만대를 출하하며 3위를 차지했습니다. 이 회사는 강력한 상업 중심 제품 포트폴리오로 2016년 2분기 이후 매년 성장률을 유지하고 있습니다.
애플은 MacBook Air와 Pro를 새로 갱신하고 노력하고 있으나 전체적으로 회사는 여전히 공급 제약에 직면하면서 해마다 긍정적인 모멘텀을 유지하기 위해 고군분투하고 있습니다.
에이서 그룹(Acer Group)은 상위에서 가장 큰 하락세에 직면하여 5위를 차지했습니다. 인텔 프로세서의 부족은 게임 및 크롬북 부문에서 회사에 영향을 미쳤습니다.
옴니비전 테크놀로지(OmniVision Techonologies)는 22일(미국시간), 자사의 이미지 센서 "OV6948"이 상용 이미지 센서에서 세계 최소형 세계 기네스 기록에 등록되었다고 발표했다.
내시경 등의 의료용 이미지 센서로 사이즈는 불과 0.575×0.575mm.
200×200도트(4만 화소) 해상도의 영상을 30fps으로 가능하며 본 센서를 탑재한 카메라 모듈 "OVM6948 CameraCubeChip"도 본체 크기가 0.65×1.158×0.65mm(폭×두께×높이)로 억제되고 있다.
고 효율적인 웨이퍼레벨 패키징 기술에 의해 소형화를 실현했고, 센서에는 백사이드 광원을 갖추고 있어 LED 광원의 발열을 억제하면서 저조도 환경 하에서도 뛰어난 이미지를 출력하는 것이 가능하다. 독자 "OmniBSI" 기술을 탑재하고 4핀 인터페이스에 의한 단순한 접속성을 실현한다.
카메라 모듈로는 120도 시야각으로 3mm~30mm의 포커스 범위를 갖추고, 아날로그 출력은 4m 이상의 전송이 가능하며 소비 전력은 25mW.
본 센서 및 카메라 모듈에 의해 신경, 안과, 이비인후과, 심장, 척추, 비뇨기과, 산부인과 및 관절 등 신체의 가장 가느다란 혈관 내 영상을 보여줄 수 있으며 수요가 계속 확대되고 있는 내시경 분야의 요구에 부응한다고 밝혔다.
ARM은 미국 새너제이에서 동사의 기술 콘퍼런스 "ARM Techcon"을 10월 8일~10일까지 개최했다. 첫날 키노트 스피치에서는 차 차세대 Cortex-A 클래스 CPU 코어 아키텍처 "Matterhorn(매터호른/매터혼)의 신 연산 명령이나 Cortex-A코어로의 사이드 채널 어택 대응 보안 기능 실장, Cortex-M의 커스텀 명령 도입, 게임 엔진 Unity의 ARM 코어군에 최적화 등이 발표되었다. 새로운 서버 CPU 코어 IP 등도 컨퍼런스 기간중에 발표될 전망이다.
Arm의 Ian Smythe(Vice President Marketing Operations, Arm)는 Cortex계 CPU 코어의 향후 기술적인 방향에 대해 설명했다.그는 업계의 트렌드로서 반도체 프로세스가 점점 복잡해져 고비용으로 변하고 있다고 지적했다. 그 문제에 대한 확실한 해답은 도메인 스페시피크(영역특화) 컴퓨팅이라고 설명한다.
또 사이버 범죄가 큰 과제가 되고 있어 제품 포커스에서 솔루션 포커스로 바뀌고 있는 것, IP의 경계를 넘어 최적화할 필요가 있음을 지적했다. 그런 문제에 대해 Arm은 시스템적 접근으로 "토탈 컴퓨트(Total Compute)"를 추진한다.
Arm이 토탈컴퓨트라고 말하는 것은 컴퓨팅의 성능을 끌어올릴 뿐만 아니라 보안이나 소프트웨어&툴까지 포괄적인 솔루션의 제안이다. 토탈컴퓨트 자체는 마케팅 캐치프레이즈지만 수요적인 요소를 포함하고 있다.
Matterhorn에서는 새 명령어 집합 ARMv8.6-A 서포트
우선 성능 확장이 도메인 스페시픽 확장으로서 심층 학습용 새 명령을 Matterhorn에 도입한다. 새 명령에 의해 기계 학습 매트릭스 연산 성능을 Cortex-A73보다 10배로 끌어올린다.
"기계 학습에서는 Cortex-A75/55에 닷 프로덕트 명령을(SIMD)에 도입했다. Cortex-A76에서는 성능을 2배로 올렸다. 그리고 Hercules 후 세대가 되는 Matterhorn에서는 k, 새로운 명령을 아키텍처에 도입한다. 매트릭스 곱셈(Matrix Multiply), 『 MatMul』라고 부르는 명령으로 CPU의 성능이 더 많이 오른다"고 Smythe는 말한다.
Arm의 Cortex-A/Neoverse 클래스 CPU 명령 세트는 "ARMv8-A", 현재 ARMv8-A는 소수점 아래 버전업이 계속되고 있다. 이번에 발표된 새로운 매트릭스 곱셈 명령 MatMul은 차기 버전의 "ARMv8.6-A"에서 끌어들인다. CPU에 벡터 명령뿐만 아니라 매트릭스 연산형의 명령이 더해지게 된다. NVIDIA가 벡터프로세서인 GPU에 본격적인 매트릭스 연산 유닛 "텐서코어"를 넣은 예와는 조금 다르다.
ARM이 ARMv8.6에서 스캔 매트릭스 명령 MatMul의 실행 유닛은 비교적 소규모 유닛이다.레지스터도 128-bit의 기존 벡터장을 쓴다. 데이터 밀도는 16-bit의 "bfloat16"에서 128-bit 레지스터에 2x4의 bfloat16 값을 다시 1개의 레지스터 2x4의 bfloat16과 곱셈, 그 결과를 32-bit 단정밀도 FP32로서 출력하고 다른 FP32 값과 가산한다. 성능 향상은 현행 Cortex-A77에 비해 5배 정도가 된다.
여기서 핵심은 ARM이 bfloat16을 데이터 포맷으로 채용한 것이다. bfloat16(Brain Floating Point 16)은 뉴럴 네트워크(용도를 전제로 제안된 새로운 부동 소수점 포맷)으로 Google이 채용하고 인텔도 이어지고 있는데 ARM도 2020년 Matterhorn 코어에서 채용한다.
기존의 IEEE 754의 부동 소수점은 FP32(32-bit 단위)가 부호부(Sign)1-bit, 지수부(Exponent)8-bit, 가수부(Mantissa) 23-bit로 구성되어 있다. bfloat16에서는 부호부(Sign)1-bit, 지수부(Exponent)8-bit, 가수부(Mantissa)7-bit와 FP32와 같은 지수부의 다이내믹 레인지를 갖춘다. 데이터 사이즈를 절반으로 하면서 다이내믹 레인지는 FP32와 비슷하다. 다이내믹 레인지가 뉴럴 네트워크에 중요한 적절한 포맷.
ARM은 심층 학습용 프로세서인 "ARM ML" 아키텍처에서는 bfloat16을 채택하지 않는다. 이는 타깃이 추론이기 때문에서 훈련에서 유용성이 높은 bfloat16은 대응하지 않았다. 그러나 CPU 측은 향후 bfloat16을 채용한다. 이는 데이터 센터 전용 Neoverse를 위한 확장으로 보인다.
사이드 채널 공격에 대한 보안 대책
보안에서는 최근 몇 년간 화제인 CPU 아키텍처에 대한 사이드 채널 공격(Meltdown, Spectre등)에 대한 대책이 꼽혔다. ARM은 이 문제에 대해 마이크로 아키텍처 레벨에서 대책을 강구한다. 구체적으로는 "메모리 태깅(Memory Tagging)", "포인터 인증(Pointer Authentication)" 등을 구현한다.
메모리 태깅은 메모리 범위에 4-bit의 태그를 단다. CPU의 메모리 액세스는 접근하는 주소를 저장한 레지스터의 태그와 메모리 태그를 비교한다. 태그는 4-bit로 작기 때문에 재이용되지만 그래도 악의 있는 프로그램의 액세스를 높은 확률로 막을 수 있다.
게임 엔진과의 제휴 발표
그 밖에 Smythe의 세션에서는 소프트웨어 에코 시스템 발전의 일환으로서 게임 엔진 벤더 Unity와의 파트너십이 발표되었다. 지금까지도 Unity의 엔진은 Arm계 SoC에 달리고 있었다.앞으로 양 회사는 파트너십을 발전시켜 보다 최적화가 진행된 소프트웨어와 하드웨어의 통합을 목표로 한다.
구체적으로는 Unity의 렌더링 파이프라인을 Arm 코어에 최적화, 멀티 코어에서의 성능을 발휘하는 멀티 스레드 코드를 생성할 수 있는 "Data Oriented Tech Stack(DOTS)"을 Arm 코어에 최적화, Unity의 AR 솔루션 "AR Foundation"도 Arm 코어의 성능을 이끌어낼 수 있도록 한다.Unity는 Unity 엔진에서 Arm의 뉴럴 네트워크 코어에도 대응한다고 밝혔다.
54 큐비트를 가진 풀 프로그래머블 프로세서 Sycamore를 이용하여 행해진 실험에서 고전적인 컴퓨터에서는 현실적으로 해결이 어려운 계산을 가능하게 하는 양자 초월성을 달성했다고 밝힌 것.
양자컴퓨터는 랜덤 양자회로를 실행하면 비트열이 생성되는데 이를 계속 반복하면 자간섭에 의해 특정 비트열이 발생하기 쉬워진다. 고전적인 컴퓨터로 이러한 조작을 행하는 경우 양자비트나 게이트 사이클이 증가함에 따라 계산량이 방대해져 발생하기 쉬운 비트열을 찾는 것이 지수 함수적으로 어려워진다.
실험에서는 우선 양자 회로의 깊이를 일정하게 유지한 상태에서 12~53큐비트의 여러 회로를 실행했다. 고전적인 컴퓨터에 의한 양자컴퓨터의 시뮬레이션을 이용하여 성능을 검증함과 동시에 이론 모델과 비교하여 동작을 확인했다. 다음 깊이가 랜덤한 53큐비트의 회로를 시뮬레이션이 불가능할 때까지 실행했다.
슈뢰딩거-파인만 알고리즘(Schrödinger-Feynman algorithm)의 양자비트 수와 게이트 사이클 수의 함수를 이용해 추정한 결과 Sycamore이 200초의 계산을 실행하고 출력한 결과와 동등한 것을 현재 세계 최고 슈퍼 컴퓨터를 이용하여 시뮬레이션하려면 10000년 걸린다고 한다.
구글은 이것으로 양자 초월성을 달성했다고 밝힌 것으로 이에 대해 미국 IBM은 구글이 진행한 실험은 계산한 벡터를 보관하는 스토리지에 대해 언급되어 있지 않은 점을 지적했다. 현실적이지 않은 방대한 메모리만을 필요로 하는 환경에서 시뮬레이션이 이루어지고 있어 메모리와 HDD를 조합해 스토리지를 대폭 확대했을 경우 보다 빨리 계산을 시행할 수 있다고 밝혔다.
IBM은 메모리와 HDD를 조합해 같은 실험을 진행한 결과 2.5일에 실행할 수 있었기 때문에 구글의 이번 발표는 "양자 초월성을 달성했다"고 말하지 못하며 이 말이 넓게 오용되고 있는 결과라고 이의를 제기했다.
미국 인텔은 산타클라라에서 열린 Linley Fall Processor Conference에서 차기 저전력 코어 Tremont의 마이크로 아키텍처를 공개했다.
저전력 IoT와 데이터 센터 전용으로 개발된 CPU 코어로 인텔의 새로운 3D 패키징 기술인 포베로스(Foveros)를 이용하여 빅코어 등과 함께 레이크필드(Lakefield)에 구현된다. Lakefield는 마이크로소프트의 2개 화면이 탑재된 Surface Neo에 채용될 예정.
트레몬트는 싱글 스레드 성능을 중시하는 것 외 네트워크 분야에서 뛰어난 전력 성능비, 면적 성능비를 실현하며 새로운 명령어도 구현된다.
높은 싱글 스레드 성능을 실현하기 위해 상위 코어 프로세서와 동급의 분기 예측이 채용되고 있으며 6 아웃 오브 오더 명령 디코딩, 4할당, 10개 실행 포트, 듀얼 로드/스토어 파이프 라인, 쿼드 코어 모듈 설계, 그리고 4.5MB 공유 L2캐시 등을 탑재한다.
인텔에 따르면 트레몬트는 동일 클럭에서 Goldmont Plus 코어와 비교하여 평균 30%가 넘는 싱글 스레드 성능 향상이 이뤄지고 있다.
글로벌 1위 소프트웨어 기업인 마이크로소프트(Microsoft)가 2019년 9월 30일 마감한 분기 실적을 발표했습니다.
발표에 따르면 매출은 전년 대비 14% 증가한 311억 달러, 영업 이익은 전년 대비 27% 증가한117억 달러, 순이익은 전년 대비 21% 증가한 110억 달러, 주당 순이익은 1.38달러로 21% 증가했습니다.
마이크로소프트의 최고 경영자 사티아 나델라(Satya Nadella)는 “세계 최고의 기업들이 디지털 기능을 구축하기 위해 클라우드를 선택하고 있습니다. 우리는 전체 기술 스택에서 혁신을 가속화하여 고객에게 새로운 가치를 제공하고 광범위한 기회를 통해 성장하는 대형 시장에 투자하고 있습니다."고 밝혔으며, 최고 재무 책임자 에이미 후드(Amy Hood)는 “상업용 클라우드가 전년 대비 36% 증가한 114억 달러의 매출을 올려 회계 연도의 강력한 시작이었다”고 밝혔습니다.
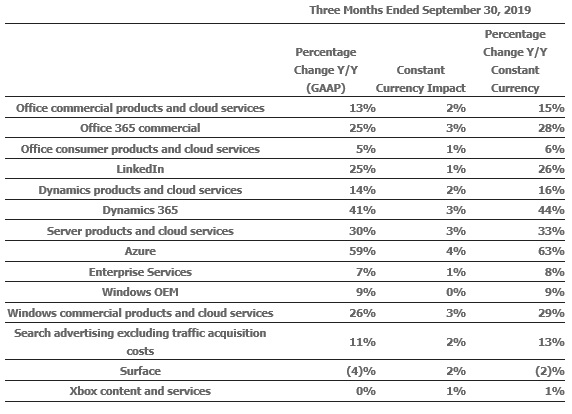
실적을 세부적으로 보면, Office 365의 상용 매출 성장이 25% 증가에 따라 Office Commercial 제품 및 클라우드 서비스 매출이 13% 증가했습니다. Office 365 소비자 가입자 수가 3560만 명으로 지속적으로 증가함에 따라 Office Consumer 제품 및 클라우드 서비스 매출은 5% 증가 했습니다.
링크드 인 매출은 25% 증가했고, Dynamics 365 매출은 41% 증가하여 Dynamics 제품 및 클라우드 서비스 매출이 14% 증가했습니다. 서버 제품 및 클라우드 서비스 매출은 애저(Azure)의 매출이 59% 증가하여 30% 증가했고, 엔터프라이즈 서비스 매출이 7% 증가했습니다.
개인용 컴퓨팅의 매출은 Windows OEM 매출이 9% 증가, Windows Commercial 제품 및 클라우드 서비스 매출이 26% 증가했습니다. 또한 트래픽 확보 비용을 제외한 검색 광고 수익은 11% 증가했고, Xbox 콘텐츠 및 서비스 매출은 상대적으로 변경되지 않았습니다.
TSMC는 실리콘 제조에 대한 접근 방식에 매우 공격적이며 현재 R&D에 더 많은 투자를함으로써 인텔의 투자와 비슷하거나 능가하고 있는 수준이다. 이는 새로운 기술에 대한 강력한 수요를 나타내며 TSMC는 더 높은 성능과 더 작은 노드에 대한 끝없는 경쟁에서 벗어날 수 없기 때문이다.
DigiTimes의 소스에 따르면 TSMC는 Southern Taiwan Science Park에 3023 헥타르 토지를 매입하여 2023년에 3nm 노드의 대량 생산을 위한 팹 건설을 시작했다. 3nm 반도체 노드는 EUV 기술을 기반으로 하는 7nm+ 및 5nm 노드인 EUV 리소그래피에서 TSMC의 세번째 시도일 것으로 예상되고 있다.