
AMD 미국 샌프란시스코 행사
AMD는 올해(2016년) 투입하는 차세대 GPU 아키텍처 "Polaris(폴라리스)"의 플래그십 GPU "Polaris 10"과 "Polaris 11"의 실제 칩 시연을 공개했다. 또 Polaris에 이어"Vega(베가)"와 "Navi(나비)"까지 로드맵을 밝혔다. 또 Fiji(피지)를 2칩 장착한 16TFLOPS의 하이엔드 제품 "라데온 프로 듀오를 발표했다. AMD APU를 탑재한 획기적인 올인원 VR(Virtual Reality)/AR(Augmented Reality)헤드셋"Sulon Q"도 소개했다.
AMD는 "CAPSAICIN"이란 컨퍼런스를 미국 샌프란시스코에서 개최했다. 새로운 GPU 로드맵과 함께 폴라리스 시연과 파트너들의 VR 콘텐츠 등 다채로운 내용을 소개했다. 회의에는 라데온 제품 그룹 총괄 Raja Koduri(라자 코두리)(Senior Vice President and Chief Architect, Radeon Technologies Group, AMD)뿐 만 아니라 AMD를 이끄는 Lisa Su(리사수)(President and CEO, AMD)도 등단했다. 또 회장에는 기술 면의 톱인 Mark Papermaster(마크 페이퍼마스터)(Senior Vice President and Chief Technology Officer, AMD)도 등단해 올 스타 멤버로서 이번 발표에 AMD가 힘을 쏟고 있음을 나타냈다.


별 시리즈가 된 AMD GPU 아키텍처 코드 네임
AMD GPU는 드디어 FinFET 3D 트랜지스터 세대에 돌입한다. 4년 이상 지속된 28nm프로세스에서 벗어나 전력당 성능을 크게 향상시킨다. FinFET의 첫 세대가 되는 폴라리스 패밀리는 올해(2016년)등장한다. 폴라리스는 28nm세대의 GPU에 대한 성능/전력이 2.5배로 높아진다는. 이는 FinFET에서 트랜지스터가 입체 구조로 되어 채널이 바디에서 거의 분리되며, 게이트 면적이 늘어남으로써 누설 전류(Leakage)의 억제가 쉽게 되기 때문이다. 성능/전력은 어떤 제품을 비교하느냐에 의해서 바뀌므로 2.5배라는 숫자는 최대 2.5배로 생각하는 게 좋을 것이다. 그래도 극적으로 전력 효율이 올라가는 것은 틀림 없다. 또한 AMD는 글로벌 파운드리의 14nm LPP 프로세스를 채용할 것으로 보인다.
AMD, GPU 아키텍처의 코드 네임은 향후 세대는 별 이름이다. FinFET의 첫세대의 Polaris(북극성)이 천구의 지침이 되는 별임은 향후 방향성을 나타내는 것을 암시하는 것으로 보인다. 2세대 베가(거문고 자리 α)는 밝게 빛나고 1등성으로 보다 성능이 올라가는 것과 관계될 것으로 보인다. 참고로, 3세대 나비(카시오페아 자리 γ)는 변칙적인 변광성으로 신비적인 거성이다. 나비라는 이름은 비운의 우주 비행사 가스 그리송(아폴로 1호 사고로 사망)의 이름을 지었다.

HBM2와 확장형 인터커넥트 시기가 분명히
이번에 폴라리스 세대는 메모리가 HBM2가 아니라 HBM1세대에 있는 것으로 드러났다. HBM2 메모리로 변하는 것은 폴라리스에 이은 베가다. AMD 차트는 폴라리스와 베가 발매 시기가 근접하고 있다. 이는 이 2개의 GPU 아키텍처가 비교적 근사한 것으로 추측된다. GPU마이크로 아키텍처적으로 베가는 폴라리스의 발전형으로 메모리 대역이 최대 2배로 오를 것으로 예상된다.
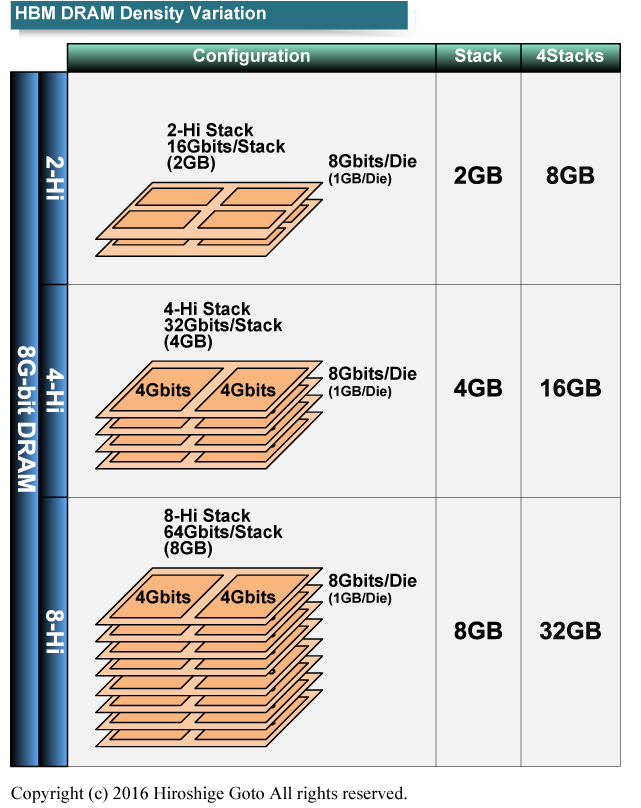
HBM2가 되면 메모리의 핀에 전송 속도가 2배가 될 뿐 만 아니라 메모리 채널의 효율이 크게 높아진다. 또 DRAM 다이의 용량이 2G-bit에서 8G-bit로 오르기 때문에 메모리 용량도 대폭 늘어난다. 현재의 HBM1 채용 GPU 피지는 4스택 구성으로 메모리 용량이 4GB지만 HBM2가 되면 메모리 용량은 최대 32GB로 8배가 늘어난다. 그래서 서버 시장에서도 매력적이다.
나비는 "Scalability(확장성)"과 "Nexgen Memory(차세대 메모리)" 2개가 타이틀이다. 확장성에 대해서는 Raja Koduri가 지난해(2015년)개요를 밝히고 있다. 그에 따르면 확장성은 멀티 GPU를 효율적으로 동작시키기 위한 플랫폼으로 GPU에 최적화한 초 광대역 인터커넥트를 도입한다. 새 인터커넥트로 GPU 뿐 만 아니라 CPU와 FPGA등도 접속할 수 있다. 또 메모리코히렌시도 이뤄질 전망이다. 작년의 단계에서 그는 도입 시기를 밝히지 않았지만 이번에 나비 세대에서 도입될 것으로 밝혀졌다. 차세대 메모리에 대해서는 현 시점에서 아직 밝혀지지 않았지만 새 메모리로는 HBM의 확장 규격, GDDR5의 후계 규격 등이 현재 거론되고 있다.
나비의 제조 공정 기술에 대해서는 로드맵상 10nm프로세스도 이용할 수 있지만 최근에는 새 프로세스를 GPU에 적용하는 것은 늦어지기 때문에 정확하지 않다.
올인원의 VR/AR기기가 실현
AMD는 이번 CAPSAICIN 컨퍼런스에서 GPU의 향후 적용 분야로서 VR/AR분야를 특히 중시하고 있음을 거듭 강조했다. 그런 노선의 최신 제품으로 AMD가 소개한 것은 "Sulon Q"다. 캐나다의 스타트 업 Sulon Technologies가 개발하는 Sulon Q는 얼핏 다른 VR 헤드셋처럼 보이지만 실태는 헤드셋 내에 컴퓨터를 내장한 PC가 불필요한 올인원 VR/AR기기다.
내장하는 것은 Carrizo(카리조)APU(Accelerated Processing Unit)기반의 "AMD FX-8800P"에 윈도우10이 운영되는 모바일 컴퓨터다. 256GB SSD에 8GB DRAM을 내장하고 디스플레이는 2560×1440의 유기 LED, 카메라도 내장하며 카메라의 화상을 끌어들임으로써 AR기기가 된다. 그것도 기존의 AR처럼 카메라 영상에 단지 오버랩하는 것이 아니라 넣은 화상에서 "공간 처리(Spatial Processing)"를 한다. "Spatial Processing Unit" 이라고 부르는 유닛을 탑재하고 있으며 실시간으로 현실 세계를 3D 매핑하고 CG와 합성한다.
AMD의 컨퍼런스에서는 Sulon의 CEO인 Dhan Balachand가 등단해 Sulon Q를 사용한 AR시연을 보였다. 시연에서는 Sulon 사무실에 AR에서 서로 겹쳐지는 마법서가 등장했다. 마법서에서 뿌려진 씨앗이 사무실의 지붕을 뚫고 덩굴을 편다. 그 지붕의 틈에서 거인이 들여다보면 Sulon Q의 유저를 잡아 올린다.
AMD GPU는 FinFET 세대의 폴라리스 이후는 저전압시 특성이 크게 높아진다. 그 때문에 이러한 올인원 VR/AR기기는 더 만들기 쉽다.

듀얼 GPU 솔루션의 최고봉 Radeon Pro DUO가 등장
AMD는 이번에 피지를 2칩 장착한 라데온 프로 듀오(Radeon Pro Duo)를 발표했다. Fiji는 HBM 메모리이므로 메모리 자체는 온 패키지로 듀얼 칩보드에서도 실장 면적은 그 만큼 크지 않다. 이러한 듀얼 GPU 솔루션도 확장형 인터커넥트를 갖춘 나비 이후에는 크게 바뀐다. GPU 들을 광대역 인터커넥트로 직결하는 것이 가능하고 확장성 면에서 크게 진화한다.
출처 - http://pc.watch.impress.co.jp/docs/column/kaigai/20160316_748463.html
랩터 인터내셔널 - http://raptor-hw.net














