AMD 불도저 아키텍처 분석 (모듈, 공유 FMAC)
 |
|
AMD는 미 스탠포드에서 개최된 칩 컨퍼런스 Hot Chips 22(A Symposium on High Performance Chips)에서 차세대 불도저 아키텍처와 밥캣의 기술적인 내용을 설명했다. 따라서 AMD의 향후 수 년간을 책임질 불도저 아키텍처를 현재까지 공개된 정보를 토대로 분석해본다. |
 |
|
이번 Hot Chips의 발표 자료로 Bulldozer와 Bobcat의 CPU 아키텍처를 대략적으로 확인할 수 있었다. Bulldozer 아키텍처의 핵심은 2개의 CPU 코어를 통합한 CPU '모듈'로 2스레드를 실행한다. 1개의 CPU 모듈안에 2개의 정수 코어(Integer Core)와 L1캐시를 갖추어 2스레드를 병렬로 실행하며 부동 소수점 유닛(FP Units)이나 명령 디코더(Instruction Decoder), L2 캐시 등은 CPU 모듈에 1개 또는 1그룹씩으로 2스레드의 공유 자원이 되고 있다. 1코어로 2스레드를 실행하는 인텔의 Hyper-Threading과 같은 SMT(Simultaneous Multithreading) 기술과는 달리 각각의 스레드의 정수 연산을 실행하는 코어는 완전하게 분리되어 있다. 또한 2개의 정수 연산 코어 각각에 정수 연산 파이프가 2개, 로드/스토어의 주소 생성 파이프가 2개로 구성 된다. 2코어로 공유되는 부동 소수점 연산 유닛부는 2개의 128-bit SIMD(Single Instruction, Multiple Data) 형태의 부동 소수점(FMAC) 유닛과 2개의 SIMD형 정수 연산 유닛을 갖추고 있다. 눈에 띄는 것은 명령과 데이터 각각의 프리패치를 강화하고 연산 유닛의 효율을 높이고 있는 점이다. 분기 예측도 강화되고 있는 것 외 Intel CPU의 Macro-Fusion 과 같은 동등한 기능 등 명령 디코드 로테이션도 강화되고 있다. 전력 효율 기능에서는 32nm 버전 K10 부터 내장되는 파워게이팅이 Bulldozer에도 채용되어 본격적으로 강화된 터보 모드도 탑재된다. 그러나 소문에 돌고 있던 트레이스 캐시 등의 채용은 없다. 전체적으로 Bulldozer는 예상대로 스레드 성능을 중시한 코어로 같은 규모의 Intel CPU보다 multi-thread 성능은 높아질 가능성이 있다. 그 반면 정수 연산계 파이프를 기존의 K7/K8/K10 계열 보다 얇게 구성하여 싱글 스레드 성능에는 불한한 요소가 있다. 그러나 AMD는 Bulldozer의 설계가 IPC(Instruction-per-Clock)의 스위트 스팟을 노린 것이며 클럭당 게이트수를 줄이는 것도 목적이라고 설계 의도를 설명한다. Bulldozer는 명령의 병렬도가 높은 CPU 코어와 비교하면 IPC는 떨어지나 전력 소비당 IPC 효율이 높고, 동작 주파수도 오를 것이라 추측된다. |
 |
|
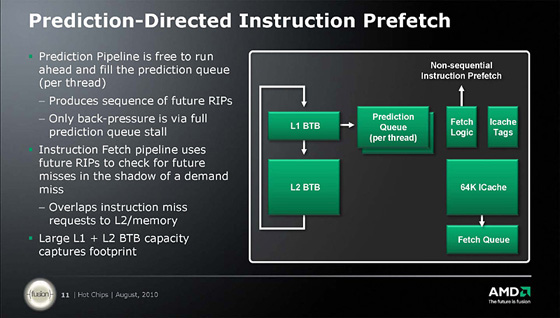
2스레드의 명령 스트림을 원활히 진행하기 위해 Bulldozer의 프론트 엔드는 기존의 K8/K10과 비교해서 상당히 강화되고 있다. 우선 예측 파이프라인이 명령어 인출 파이프로부터 독립하여 동작한다. 예측 유닛에 가이드 된 명령을 프리패치 유닛이 명령을 예측한다. L1명령 캐시로부터 명령어 인출의 패치 대역은 32-byte폭. 큐는 스레드에 맞춰 이중화 되고 있을 가능성이 있다. 명령 디코더는 최대 4개의 x86 명령을 내부 명령으로 디코드할 수 있다. 명령 디코더는 인텔의 Macro-Fusion과 같이 비교 명령과 조건 분기 명령을 융합시키는 것으로 명령어 수를 줄이는 기능을 갖춘다. 이 때문에 디코더의 명령어 인출수는 최대 5개의 x86 명령이라 추정된다. 여기까지의 프론트엔드 부분은 사이클 단위로 스레드를 스위치 하거나 큐를 2중화하는 등의 방법에 의해서 2개의 스레드로 공유되고 있다. 2개의 정수 연산 코어는 같은 기능을 갖는다. 명령어 인출 유닛에서는 최대 4개의 명령이 각각의 정수 명령 스케줄러에 접속된다. 연산 파이프는 2개로 통상적인 연산 회로 외에 다른 한쪽의 파이프가(MUL:Multiplier), 다른 한쪽의 파이프가 DIV:Divider 를 갖추고 있다. 그 외에 로드/스토어의 주소 생성(Address Generation) 파이프가 2개 있다. 명령 디코드측이 2 명령/스레드/클럭이라고 볼 수 있는데 파이프라인이 4개인 것은 x86 명령 가운데 연산과 메모리 엑세스가 혼합한 명령이 연산 Micro-OP 와 메모리 엑세스 Micro-OP로 분리되기 위해서라고 추정된다. 각각의 정수 코어의 로드/스토어 유닛은 2개의 128-bit 로드와 1개의 128-bit 스토어를 1사이클로 동시에 실행할 수 있다. 16KB의 L1 데이터 캐시는 3개의 메모리 작업을 동시에 진행할 수 있다. 다만, 주소 생성은 2 파이프 밖에 없다. 레지스터는 물리 레지스터를 레지스터 리네이밍으로 매핑 하는 방식을 택하고 있다. 이것은 데이터 이동을 최소화 하기 위해서다. 각각의 스레드의 명령 인출은 정수 연산 유닛내에서 시행한다. |
 |
|
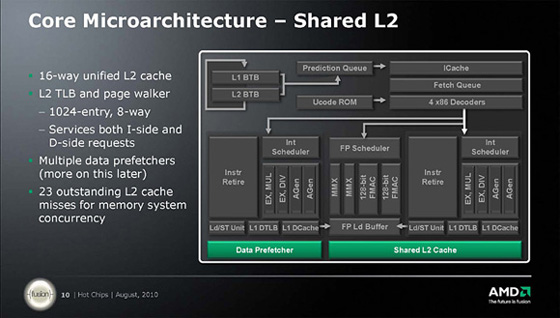
부동 소수점(FP) 연산 유닛은 코-프로세서(Co-Processor)적인 발상으로 만들어져 있다. 불도저의 FP유닛은 정수 유닛에 종속되는 형태로 로드/스토어 명령도 정수 유닛측에서 실행되어 FP 유닛내에는 L1 데이터 캐시도 갖추지 않고 로드 버퍼만을 갖는다. 연산 파이프는 2개의 128-bit SIMD(Single Instruction, Multiple Data) 형태의 부동 소수점(FMAC) 유닛과 2개의 128-bit SIMD형 정수 연산 유닛, 부동 소수점 연산계열과 정수 연산계열이 분리되어 있다. 또, 부동 소수점 연산 파이프는 다수의 스레드의 명령을 1 사이클에 혼재할 수 있는 SMT(Simultaneous Multithreading)로 실행이 되어 있다. 2개 스레드의 부동 소수점 연산 명령을 동시에 실행할 수 있다는 점. Bulldozer 모듈의 L2캐시는 2개의 정수 코어로 공유되고 있다. L1과 L2의 데이터 프리패치는 크게 강화되었다. 규칙적인 데이터를 프리패치하는 스트라이드 베이스드(Stride-Based) 뿐 만 아니라 데이터가 불규칙 적으로 어려운 경우에도 대응할 수 있는 프리패치를 갖춘다. 또, 예측에 의해서 데이터 대역을 압박하는 프리패치를 로드되는 양에 따라 유지시키는 메커니즘도 갖춘다. 전력 효율 기능에서는 모듈 단위로 전원을 완전하게 OFF 할 수 있는 파워게이팅을 탑재한다. AMD는 6코어 CPU 투반에 이미 터보 모드를 적용했다. 투반의 터보 모드는 3코어 단위로 동작하지만 Bulldozer의 터보 코어는 이것보다 더 세부적으로 확장되고 있는 것으로 보인다. Bulldozer의 이점은 코어의 갯수라는 multi-thread 퍼포먼스다. AMD는 Intel의 6코어(12스레드) CPU에 Bulldozer 베이스의 8코어(4모듈) CPU를 대응, Intel의 상위 10코어(20스레드) CPU에는 16코어(8모듈, 2다이) CPU를 대응 시킬것이라 추정된다. 서버 전용의 Bulldozer 8코어는 Valencia(발렌시아), 16코어는 Interlagos(인터라고스), 데스크탑 전용의 8코어는 Zambezi(잠베지). Interlagos는 DDR3 쿼드 메모리 채널의 소켓 G34, Valencia는 DDR3 듀얼 메모리 채널의 소켓 G32. 모두 GPU 코어는 통합하지 않고, CPU 코어와 노스 브릿지의 기능을 탑재한 CPU로, 지원하는 메모리는 DDR3의 새로운 차기 스펙인 1.25V의 지원이 추가된다. |
'랩터 애널리시스' 카테고리의 다른 글
| 오픈플로우 컨트롤러, 소프트웨어 정의 네트워크 (0) | 2016.04.24 |
|---|---|
| 구글 스마트 컨택트 렌즈 개발 (0) | 2016.04.24 |
| 인텔 네할렘 아키텍처, 로드맵 분석 (SMT,터보부스트) (0) | 2016.04.23 |
| 인텔 샌디브릿지 아키텍처 분석 (링버스,AVX,SSE,uOP 캐시) (0) | 2016.04.23 |
| 시스코, 사물인터넷 시대에 대응하는 포그 컴퓨팅 플랫폼 IOx 발표 (0) | 2016.04.23 |




