= Broadwell-Y
2014년이 마무리되고 2015년 새해가 밝았다. 2015년부터 IT 업계는 반도체를 중심으로 다양한 신기술 및 신제품과 함께 역동적인 한해가 될 것이라 예상되고 있는 가운데 그 중심에 있는 아키텍처(하드웨어) 테크놀로지 동향을 중점적으로 살펴보도록 한다.
우선 나노 공정, 아키텍처 기술의 리딩 이노베이터라 불리는 인텔은 14나노 세대의 프로세서 군과 이것이 탑재되는 다양한 신제품들을 대거 공개했다. 인텔의 틱(TICK)-톡(TOCK) 전략(한해에는 진보된 프로세스로 이전 / 다음해는 새로운 아키텍처 도입)에 따라 기존 하스웰(22나노)의 14나노 이행 버전인 브로드웰-Y / 브로드웰-U가 본격적으로 시장에 전개되기 시작했다.
| 4세대 코어 Y 프로세서 | 5세대 코어 M 프로세서 |
|---|
| 코드네임 | 하스웰 (Haswell-Y) | 브로드웰 (Broadwell-Y) |
| 프로세스 | 22나노 | 14나노 |
| 트랜지스터 | 9억 6000만 | 13억 |
| 다이사이즈 | 131mm2 | 82mm2 |
| 코어/스레드 | 2/4 | 2/4 |
| L3 캐시 | 3MB | 4MB |
| GPU | Gen7.5(Intel HD Graphics 4400) | Gen8(Intel HD Graphics 5300) |
| EU | 20 | 24 |
| 메모리 | LPDDR3/DDR3L(최대 1,600MHz) |
| TDP | 11.5W | 4.5W |
| 패키지 | 24×40×1.5mm | 16.5×30×1.05mm |
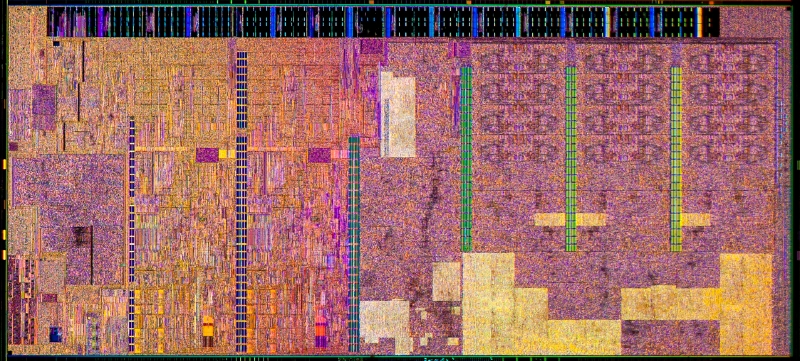
먼저 선보인 브로드웰-Y는 CORE M 브랜드로 구분되는 프로세서 군으로 2-IN-1 디바이스를 주 타켓으로 한다. 일반적으로 프로세스가 미세화 되면 퍼포먼스가 향상 됨과 동시에 소비 전력이 감소하는 기본적인 이점에 따라 기존의 4세대 코어 Y 프로세서에서 5세대 코어 M 프로세서로의 진화도 인텔이 업계 최초로 도입한 최첨단 14나노 공정이 적용되어 다이 사이즈가 131mm2에서 82mm2로 소형화, 트랜지스터는 13억, L3 캐시는 4MB, 실행 엔진(EU)가 24개로 향상된 8세대 인텔 HD 그래픽스 5300이 탑재되어 각각의 부문이 강화 되면서도 TDP는 4.5와트로 감소했다. (IPC=Instruction Per Cycle 5% 상승)
퍼포먼스는 향상됐으나 TDP 감소와 다이사이즈 감소에 따른 패키지 사이즈도 감소되어 각각의 제조사들은 보다 얇고 가벼운 팬리스 디바이스를 제조하는데 한결 수월하게 된다.
| 5Y31 | 5Y51 | 5Y71 | 5Y10c | 5Y10 | 5Y10a | 5Y70 |
|---|
| 캐시 | 4MB |
| 클럭 | 900MHz | 1.10GHz | 1.20GHz | 800MHz | 800MHz | 800MHz | 1.10GHz |
| 코어/스레드 | 2/4 |
| TDP | 4.5W |
| 메모리 | LPDDR3 1600/1333, DDR3L/DDR3L-RS 1600 | DDR3L-1333/1600 |
| LPDDR3 1333/1600 |
| 그래픽 | Intel HD Graphics 5300 |
CORE M은 5Y31부터 5Y51 / 5Y71 / 5Y10c / 5Y10 / 5Y10a / 5Y70 으로 라인업되며 인텔에 의하면 기존 하스웰-Y와 비교시 CPU 성능은 12~19% 향상, GPU 성능은 47% 향상, 배터리 구동시간은 35Wh 용량 기준으로 웹 브라우징시 7.4시간 -> 8.4시간, 비디오 재생시 6.9시간 -> 8.6시간으로 향상된 것으로 나타나고 있다.
= Broadwell-U
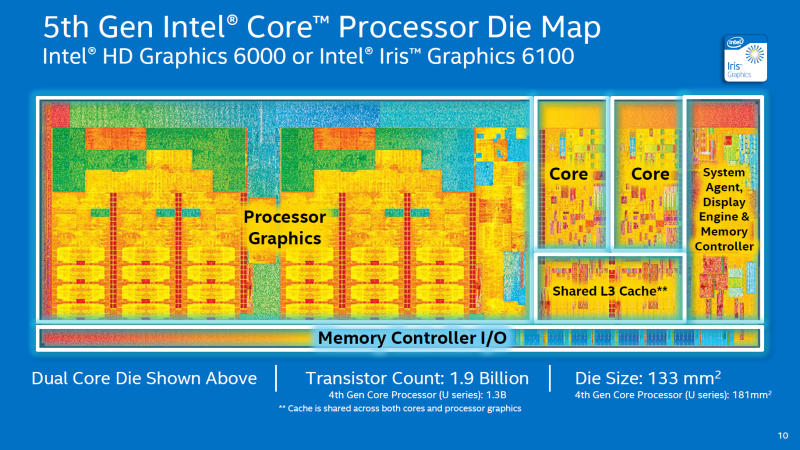
인텔은 최근 2015 International CES에서 브로드웰-U 프로세서를 공식 발표했다. 브로드웰-U는 기존의 하스웰-U를 대체하는 프로세서로 브로드웰-Y 와 같이 14나노 공정으로 제조된다.
앞서 설명한 브로드웰-Y가 4.5W TDP로 2-IN-1 디바이스를 주 타겟으로 한다면 브로드웰-U는 15W~28W의 TDP로 울트라북 / 노트PC 및 일부 All-in-one 시장까지 타겟으로 하는 프로세서.
브로드웰-U 또한 14나노 공정으로 다이 사이즈가 131mm2에서 82mm2로 37% 감소, 트랜지스터는 9억 6천만에서 13억으로 35% 증가했고, 상위 인텔 아이리스 그래픽 탑재 모델은 다이 사이즈가 181mm2에서 133mm2 로 감소하고 트랜지스터는 13억에서 19억으로 증가했다.
| BASE | BOOST | GPU | CLOCK | LPDDR3 | L3 | TDP |
|---|
| i7-5650U | 2.2 | 3.2 | HD 6000 | 300/1,000 | 1866 | 4MB | 15W |
| i7-5600U | 2.6 | 3.2 | HD 5500 | 300/950 | 1600 | 4MB | 15W |
| i7-5550U | 2.0 | 3.0 | HD 6000 | 300/1,000 | 1866 | 4MB | 15W |
| i7-5500U | 2.4 | 3.0 | HD 5500 | 300/950 | 1600 | 4MB | 15W |
| i5-5350U | 1.8 | 2.9 | HD 6000 | 300/1,000 | 1866 | 3MB | 15W |
| i5-5300U | 2.3 | 2.9 | HD 5500 | 300/900 | 1600 | 3MB | 15W |
| i5-5250U | 1.6 | 2.7 | HD 6000 | 300/950 | 1866 | 3MB | 15W |
| i5-5200U | 2.2 | 2.7 | HD 5500 | 300/900 | 1600 | 3MB | 15W |
| i3-5010U | 2.1 | N/A | HD 5500 | 300/900 | 1600 | 3MB | 15W |
| i3-5005U | 2.0 | N/A | HD 5500 | 300/850 | 1600 | 3MB | 15W |
| i7-5557U | 3.1 | 3.4 | Iris 6100 | 300/1,100 | 1866 | 4MB | 28W |
| i5-5287U | 2.9 | 3.3 | Iris 6100 | 300/1,100 | 1866 | 3MB | 28W |
| i5-5257U | 2.7 | 3.1 | Iris 6100 | 300/1,050 | 1866 | 3MB | 28W |
| i3-5157U | 2.5 | N/A | Iris 6100 | 300/1,000 | 1866 | 3MB | 28W |
라인업을 보면 TDP 15W의 HD 그래픽 탑재 모델이 10종, TDP 28와트의 아이리스 그래픽 탑재 모델이 4종으로 각각의 모델은 동작 클럭과 최대 클럭, L3, 내장 GPU, GPU 클럭 등의 차별성이 있고, 프로세서는 모두 듀얼 코어 베이스에 Hyper-Threading 대응으로 4스레드로 동작한다. 인텔에 의하면 브로드웰-U는 기존 제품들과 성능 비교시 3D 그래픽에서 22%, 동영상 변환 50%, 업무 프로그램은 4% 향상되며 배터리 지속 시간은 1.5시간 증가된다고 어필하고 있다.
그 외 브로드웰에는 리얼센스(RealSense)라 불리는 3D 카메라를 이용한 3D 스캐닝과 음성 인식 소프트웨어 드래곤 어시스턴트(Dragon Assistant)를 이용한 음성 조작, vPro, 무선 디스플레이 와이다이(WiDi 5.1) 기술 등의 부가 기능을 지원하고 있다.
인텔은 14나노 세대의 브로드웰 아키텍처에 이어 TICK-TOCK 전략의 TOCK에 해당하는 새로운 아키텍처 베이스의 스카이레이크 또한 올해 하반기경 발표할 예정이다. 스카이레이크에 관한 정보는 14나노로 제조되는 새로운 세대의 아키텍처, 향상된 전력 컨트롤 기술, 본격적인 DDR4 시대로의 진입 외 세부적인 정보는 아직 공개되지 않았기 때문에 추후 업데이트 되는 정보들을 확인 할 필요성이 있다.

= EDISON
인텔은 IT 업계의 화두인 사물 인터넷(IOT)과 웨어러블 분야에서도 발 빠른 행보를 보이고 있다.
지난 2014년 선보인 SD 카드 사이즈 급의 초소형 플랫폼 에디슨(EDISON)은 태블릿 디바이스에 탑재되고 있는 실버몬트 아키텍처 베이스의 커스텀 듀얼코어, 4GB eMMC, IEEE 802.11a/b/g/n 무선 네트워크, 블루투스 4.0 + 2.1 EDR 기능 등을 갖춘 초소형 X86 컴퓨터로서 단순히 하드웨어 만을 제공하는 것이 아니라 개발 보드 및 개발 킷, 상세 메뉴얼 등을 공식 사이트에서 제공하고 있기 때문에 사물 인터넷을 위한 디바이스 및 관련 사업을 전개하려는 개발자 및 업체들이 에디슨을 기반으로 다양한 프로젝트를 진행 할 수 있도록 서포트하고 있다.
2014년 사물 인터넷을 위한 에디슨 발표 이후 인텔은 최근 2015 International CES에서 웨어러블 디바이스를 타겟으로한 Curie(큐리)를 발표했다. 큐리는 단추 사이즈 급에 Quark SE SoC, 384KB 플래시 메모리, 80KB SRAM, DSP 허브, Bluetooth LE, 오픈소스 OS 등을 갖춘 웨어러블 디바이스 타겟의 초소형 X86 모듈로 개발자들을 위한 IQ 소프트웨어 킷이라는 전용 캐발킷 또한 제공되어 웨어러블 사업 전개를 위한 접근성과 관련 사업을 서포트하고 있다.
이러한 사물 인터넷의 에디슨, 웨어러블의 큐리와 같이 인텔은 매년 진화된 초소형 플랫폼들을 선보이며 사물 인터넷과 웨어러블 시장에서도 강력한 "인텔 인사이드"를 추진하여 X86 아키텍처가 IT 전역으로 확대됨에 따라 관련 사업을 전개하는 각각의 IT 개발자, IT 기업들은 "IT 통합 X86 시대"의 흐름에 따른 정책과 전략을 수립하여 경쟁력을 확보해야 할 것이다.

= HSA FOUNDATION
인텔과의 프로세서 아키텍처 경쟁에서 밀려 현재까지도 고전하고 있는 AMD는 인텔과는 다른 방향성을 나타내고 있다.
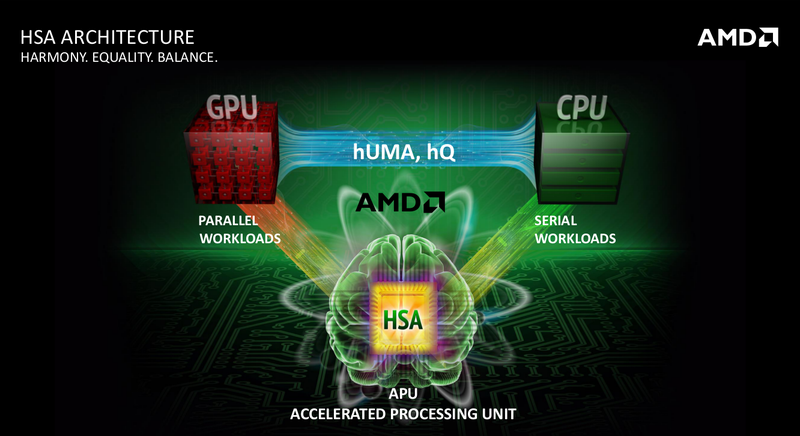
그것은 HSA(Heterogeneous System Architecture)라 불리는 CPU 이외의 GPU 등의 프로세서를 융합하여 프로세스의 성능을 극대화 한다는 개념으로 지난 2012년 6월, AMD가 주축으로 HSA FOUNDATION을 창립하고 ARM, 퀄컴, 이매지네이션, 미디어텍, 삼성 등의 주요 기업들이 모두 참여하고 있다.
= HSA SOFTWARE LAYER
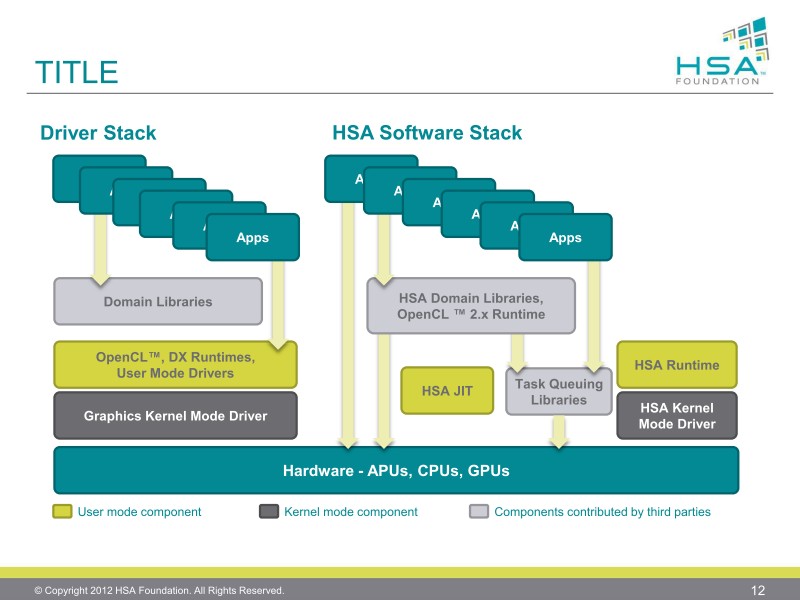
HSA의 소프트레이어는 GPU의 드라이버와 같은 소프트웨어 층과 별도로 새로운 HSA 층을 제공한다. 기존의 GPU 드라이버 층에 신규 HSA 소프트웨어 층이 추가되는 형태로서 HSA는 이러한 소프트웨어 층을 실현하기 위해 가상 명령어 아키텍처, 큐잉 등을 정의한다.
세부적으로는 다수의 프로세서 제조사 칩 사이에 ISA를 통합하고, 런 타임 컴파일러가 가상 ISA에서 고유의 네이티브 ISA로 변환한 뒤 HSA 모델이 가상 ISA를 HSAIL(HSA Intermediate Language)로 통합하여 HSAIL을 네이티브 ISA로 컴파일해 런타임 시스템으로 동작하는 원리다.
HSA의 이러한 이론이 의미하는 것은 아키텍처가 서로 다른 프로세서 간의 프로세스를 연계 호환(동작) 시킬수 있다는 것.
= HSA SHARED VIRTUAL MEMORY
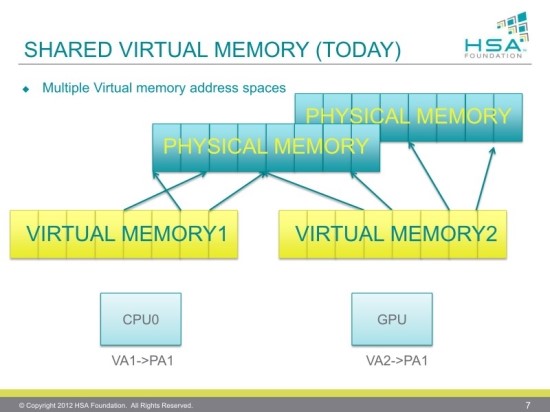
HSA 기술의 하드웨어 부문과 소프트웨어 부문을 연결하는 HQ(Heterogeneous Queuing)는 CPU 코어와 GPU 코어를 묶기 위한 중요한 기술이며 가상 메모리 공유 사양 hUMA(heterogeneous Uniform Memory Access)와 연계되어 동작한다.

= Heterogeneous Queuing
일반적인 GPU 프로세스는 특정 애플리케이션의 명령 - 다이렉트 3D - 유저 모드 드라이버 - 소프트 큐 - 커널 모드 드라이버 - 하드웨어 큐 - GPU 하드웨어로 전송되는 구조로서 소프트웨어 층이 두껍고 복잡하여 오버헤드와 레이턴시가 높다.
기존 모델에서 오버헤드가 높은 이유는 CPU 상의 커널 드라이버가 큐를 관리하기 때문에 반드시 CPU 개입이 필요하고, 각각의 GPU 벤더에 따른 각기 다른 큐 포맷으로 변환 작업과 GPU 코어에 대한 디스패치를 CPU 프로세스의 핸들링에 의존해야 하는 한계가 있기 때문이다.
이러한 문제들을 HSA는 유저 모드 큐잉 도입, 디바이스의 큐 처리, HSA 벤더간 표준화 된 패킷 포맷과 큐잉 언어 정의, GPU의 디스패치 등을 hQ(Heterogeneous Queuing)로 처리한다. 따라서 GPU가 스스로에게 큐를 할 수 있도록 하고 CPU 코어에도 HSA 태스크 큐잉 런타임으로 hQ 포맷의 패킷을 실행할 수 있도록 하여 GPU 코어에서 CPU 코어로 작업을 전달 할 수 있도록 한다.
결과적으로 CPU 코어와 GPU 코어 양쪽이 같은 프레임워크에서 작업을 처리하고 코어간 자유롭게 작업을 건넬 수 있는 아키텍처를 구축한다는 것이다.
= HSA FUTURE
HSA는 메모리의 주소 공유 문제와 실행 큐를 CPU와 GPU에서 어떻게 공유 할 것인가 라는 두가지의 과제를 안고 있다. 현재 개발자는 프로그래밍시 CPU와 GPU를 각각 어떤 메모리 주소인지를 의식하여 처리해야하는 문제가 있는데 이것의 해답으로 AMD는 HUMA 아키텍처로 하드웨어 제어 양방향 메모리로 명시적인 데이터의 이동을 없애고, HSA 에이전트 간의 통신 신호를 별도로 정의하며 CPU와 GPU가 통합 메모리 주소를 공유하게 하여 개발자가 하나의 메모리 주소로 명시하여 프로그래밍 할 수 있게 한다. 또 실행 큐의 공유 문제는 HQ로 프로그램이 발행한 명령을 CPU가 처리할 것인지 또는 GPU가 처리할 것인지를 자동적으로 분류시켜 동작 시킬수 있다는 것.
지난해 2014년 1월 AMD는 이러한 HSA 기술의 중간 결과물로 카베리(Kaveri)를 발표했다. 발표된 카베리는 스팀롤러 CPU 코어와 라데온 GCN GPU 코어를 탑재하고 HSA를 실현하는 hUMA와 hQ 기능을 실현한 제품으로 밝혀져 업계의 이목을 집중시켰다.
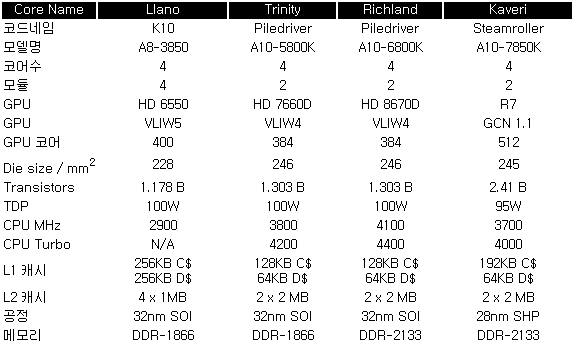
발표된 카베리는 기존의 라노 - 트리니티 - 리치랜드에 적용된 32나노 SOI 프로세스에서 28nm SHP 프로세스로 이전되어 캐시, 트랜지스터, GPU, CPU, IPC 등이 향상 되면서도 TDP는 95W로 감소했다.
기대를 받았던 카베리의 퍼포먼스는 HSA를 적용하지 않은 일반적인 각각의 CPU / GPU 부문에서 눈에 띄는 성능 향상은 없었고, 제조 공정 이전에 따른 각 유닛 강화에 따라 이전 세대 리치랜드의 마이너 업그레이드 모델로 평가됐다. 그러나 HSA를 적용한 Libre Office, Aftershot Pro 등과 같은 일부 부문에서는 10~20% 정도 추가적인 성능 향상이 나타나면서 HSA가 페이퍼 기술이 아닌 어느 정도 충분한 가능성을 내포하고 있다는 점을 입증하게 된다.
아키텍처 관련 비공식 소식통에 따르면 AMD가 발표한 카베리는 HSA FOUNDATION의 1.0 규격을 모두 준수하지 않은 설익은 제품이라는 점과 HSA 1.0 규격을 모두 준수한 실질적인 첫번째 HSA 제품은 카리조(Carrizo)라는 정보가 전해지고 있다. AMD는 최근 2015 International CES에서 카리조의 엔지니어링 샘플이 탑재된 노트북으로 4K 해상도로 H.265를 재생하는 정도의 정보만 공개하고 세부적인 부문은 언급하지 않았다. 카리조의 스케줄은 COMPUTEX에서 공식 발표 후 올해 하반기경 시장 발매가 예상되고 있다.
"카리조가 실질적인 HSA 1.0 제품이다" 라는 내용의 진위 여부를 떠나 카베리는 HSA 지원 S/W에서 성능이 향상된다는 점을 입증하고 있기 때문에 향후 S/W 업계와의 긴밀한 연계, 또한 HSA FOUNDATION 멤버들과의 활발한 콜라보레이션으로 향후 순차적으로 선보일 HSA 결과물 들을 지켜 볼 필요성이 있고, AMD는 그보다 먼저 근본적인 경쟁력 확보를 위한 "순수한 CPU 아키텍처 혁신" 도 반드시 이뤄내야 한다는 점을 각인해야 할 것이다. (루머에 의하면 AMD는 새로운 X86 아키텍처 ZEN을 2016년 발표할 예정)
= HBM (High Bandwidth Memory)
이번에는 메모리 아키텍처로 화제를 돌려본다.
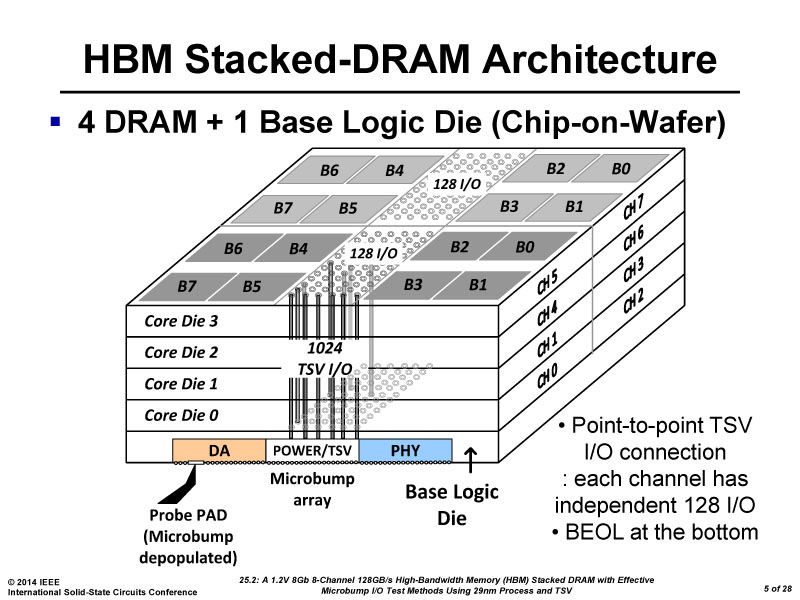
JEDEC(반도체 표준화 단체)는 기존 GDDR5의 후계 광대역 메모리 기술로 HBM(High Bandwidth Memory)를 규격화 했다. DDR 메모리 기술의 연장선으로 오랜 기간 동안 GPU에 사용된 GDDR5는 퍼포먼스 향상과 전력 소모 억제라는 부분에 한계에 도달하며 새로운 GPU 아키텍처 개발에도 제약이 된다.
CPU와 마찬가지로 GPU 또한 고대역과 퍼포먼스를 끌어올리면서 대역당 소비전력을 낮추는 것, 이러한 시장 요구에 따라 SK 하이닉스가 실현하는 HBM 기술이 부상하기 시작한다.
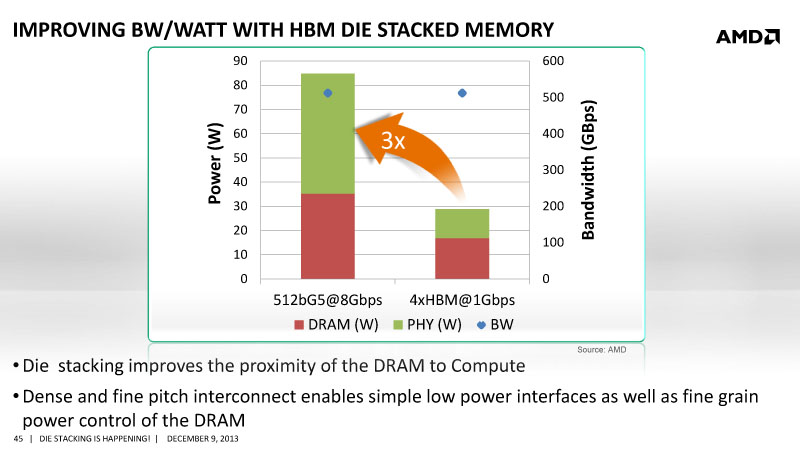
HBM은 이론적으로 GDDR5와 비교시 최소 3배 이상의 퍼포먼스와 광대역을 실현하면서도 저전력의 강점을 갖는다. SK 하이닉스+AMD의 발표에 의하면 HBM의 소비 전력은 GDDR5에 비해 압도적으로 낮아 4개 스택으로 구성된 HBM DRAM을 1Gbps로 구성해도 소비 전력은 30W 이하로, 이것을 GDDR5에서 실현할 경우 소비 전력은 최소 80W 이상을 필요로 한다는 것.
= HBM POWER

= GDDR5 vs HBM
HBM의 초기 모델로 기존 GDDR5와 비교시에도 버스폭이 32bit에서 1024bit로, 이에 따른 대역폭은 28GB/s에서 100GB/s로, 이것을 더 낮은 클럭과 전력으로 실현 할 수 있다는 것이며 이러한 와트당 대역(BW / WATT)의 수직 향상, 이것을 기반으로 각 벤더는 칩 설계시 더 높은 와트당 성능(PERFORMANCE / WATT)을 갖춘 GPU를 개발할 수 있게 되며 전통적인 VGA, SOC 외에도 HPC , 서버 등 다양한 부문에 적용할 수 있다.
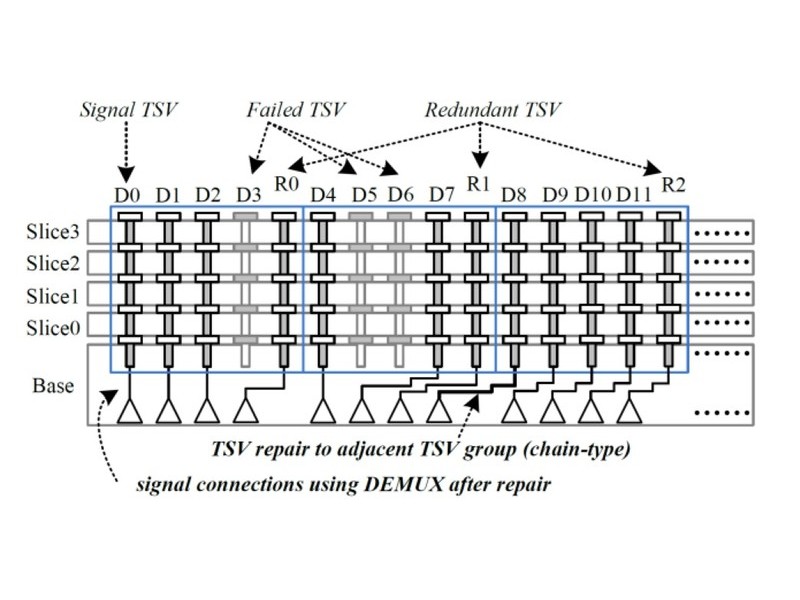 = Through Silicon Via
= Through Silicon Via
현재 일반적인 실리콘 칩은 다이의 한쪽에만 단자를 구성할 수 있기 때문에 각 다이를 와이어로 연결하는 와이어 본딩 배선이 사용되고 있다. 그러나 TSV를 적용하면 다이의 실리콘 기판을 관통한 각각의 구멍으로 다이의 후면에도 단자를 배치하여 직접 연결할 수 있다.
또한 와이어 본딩에 의한 배선은 칩간 물리적인 배선수가 한정되어 있는 반면 TSV는 다이 사이를 수천 단자로 연결이 가능해 이론적으로 기존 DRAM 칩의 수십 배에 달하는 인터페이스를 비교적 낮은 클럭 속도로 구현하여 광대역 메모리를 실현할 수 있다.
와이어 본딩 기술의 와이어는 그 자체가 얇고, 금속 와이어에 의한 기생 저항으로 신호 전송을 지연시켜 고속화를 방해하는 부문에서도 TSV는 더 자유로울수 있으나 수많은 전극을 형성함에 따른 비용 증가, 관통 전극에 의한 실리콘 면적 증가, 제품 수율 등에 따른 높은 비용이 단점으로 지적되고 있다.
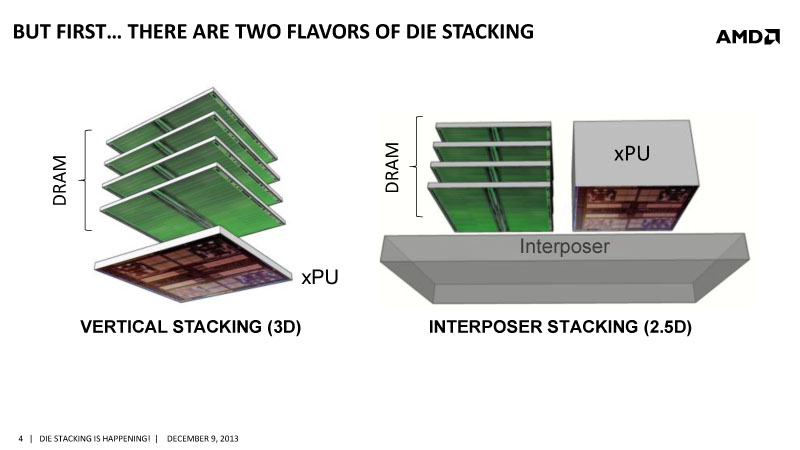
= HBM 3D / 2.5D
HBM 아키텍처는 크게 2가지로 분류된다. TSV 기술로 DRAM / GPU / CPU를 직접 연결하는 3D 적층과 실리콘 인터포저(Interposer) 또는 TSV 인터포저를 사용해 연결하는 2.5D 적층.
3D와 2.5D 기술의 차이점은 3D 적층은 GPU/CPU와 같은 로직 칩에도 TSV로 구멍을 뚫을 필요가 있는 반면 2.5D는 로직 칩에 TSV 로 구멍을 뚫지 않아도 되기 때문에 각각의 CPU / GPU 벤더가 적용하기 유연하다. 3D 방식은 공간 활용면에서는 이점이 있으나 실질적으로 발열성이 높은 CPU, GPU 등의 칩을 DRAM과 직접 연결시켜 적층 할 경우 열 설계 문제에 직면하게 된다.
이러한 기술적 한계에 따라 HBM 기술은 2.5D를 주축으로 개발이 진행된다. 2.5D는 CPU, GPU 각 벤더의 논리 칩이 독립적으로 위치되고 그 측면으로 적층된 DRAM, 그리고 논리 칩과 DRAM을 인터포저가 연결하는 구조로 각 벤더가 빠르고 유연하게 적용할 수 있다.

= 2.5D DETAIL
비공식 업계 정보에 의하면 SK 하이닉스는 2014년 하반기부터 HBM 출하를 시작한 것으로 보고 되고 있다. HBM을 최초로 적용한 제품은 AMD가 올해 발표를 예정으로 개발중인 코드네임 FIJI XT(라데온 3XX)가 그 주인공이 될 것으로 보인다.
엔비디아 또한 파스칼(PASCAL)로 불리는 현행의 맥스웰 다음 차기 아키텍처에 SK 하이닉스의 HBM이나 마이크론 테크놀로지의 Hybrid Memory Cube(HMC) 와 같은 TSV기반 스택 메모리 기술 탑재를 공식적으로 언급하면서 차세대 GPU들의 방향성은 이미 뚜렷하게 나타나고 있다.
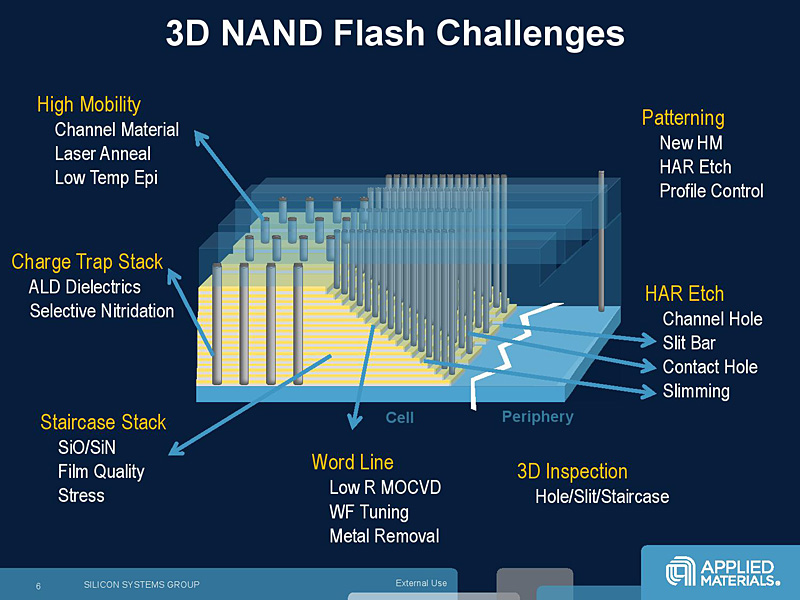
= 3D Vertical NAND
한편, 낸드 플래시 아키텍처 부문에서는 삼성전자가 선도하고 있는 3D V-NAND 기술을 살펴 볼 필요성이 있다.
기존 2D NAND는 게이트에 전하를 저장하는 방식으로 플로팅 게이트(Floating Gate) 구조를 적용하여 미세 나노 공정으로 이전 될 수록 셀간 간격이 좁아져 전자가 누설되는 간섭 현상 심화에 따라 비트/셀의 대용량화가 둔화되는 등 미세화 기술이 물리적 한계에 도달했다.
이러한 상황을 타개하고자 NAND 메모리 셀을 수직(Vertical)으로 적층하여 대용량화 한다는 방법론이 부상한 것으로서 3D NAND 이론 자체는 지난 2007년 도시바가 먼저 발표했고 삼성전자도 연구 개발을 함께 추진한 것으로 양산 단계에서는 삼성전자가 먼저 선착하면서 관련 사업을 리드하고 있는 것.
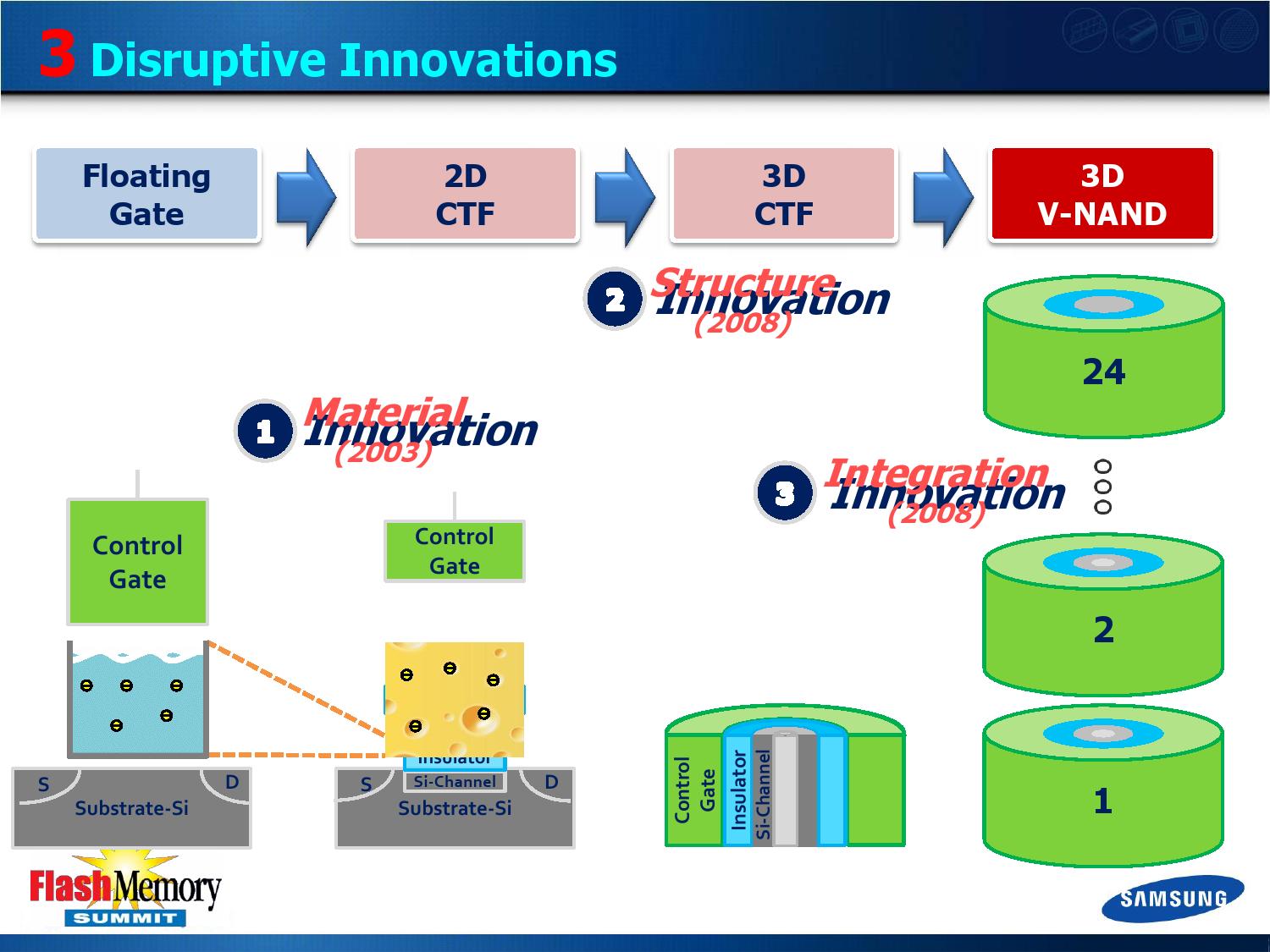
= 3D Vertical EX
삼성전자가 최초 선보인 V-NAND는 메모리 셀을 기존과 같은 플로팅 게이트 구조가 아닌 차지 트랩(Charge Trap Flash)을 사용하며 수직으로 연결 된 채널 라인을 따라 메모리 셀을 연속 생성하여 24단으로 스택했다.(128G-bit) 발표된 24단 V-NAND는 30nm 공정의 MLC(Multi-Level Cell) 방식으로 20나노 NAND와 비교시 2배의 밀도와 향상된 퍼포먼스, 신뢰성, 소비전력에서 강점을 갖는다고 어필했다.
3D NAND의 강점은 프로세스 공정에 크게 의존하지 않고 대용량화가 유연하다는 점으로 미세 공정에 의존하고 있는 기존 2D NAND 벤더들과의 경쟁에서 강력한 무기가 될 수 있다.

= 32 STACK 3D Vertical NAND
삼성전자는 최초 발표한 1세대 V-NAND에서 2-bit/Cell의 MLC(Multi-Level Cell) 메모리 셀을 24단으로 스택한 128G-bit(16GB) 칩을 실현했고, 이어 기술 진화에 따라 MLC 셀을 32단으로 스택, 메모리 셀 밀도를 30% 이상 향상시키면서 셀 면적을 70%로 줄인 2세대 V-NAND 128G-bit 칩을 발표한다.
2세대 기술 발표 이후 삼성전자는 3D V-NAND가 실제로 탑재된 첫번째 850PRO SSD를 시장에 발표하면서 낸드 플래시 시장의 리딩 이노베이터 임을 강하게 어필한다. 3D V-NAND 탑재 SSD 제품으로는 "세계 최초"의 타이틀로 공개 된 850PRO SSD는 등장과 동시에 PC 시장의 2.5인치 SSD 왕좌를 차지한다. [ 850 PRO 벤치마크 - http://raptor-hw.net/xe/index.php?mid=benchmark&page=2&document_srl=13050 ]
또, 2014년 8월에는 V-NAND의 3세대가 되는 3-bit/Cell(TLC) V-NAND를 발표한다. 3세대 V-NAND는 기존 2세대와 같은 32단으로 스택되나 1셀당 비트를 2-bit에서 3-bit로 늘린 TLC(Triple-Level Cell)로서 보다 더 고밀도화에 성공하면서 3D V-NAND 시장에서 독주를 지속하고 있다.
물론 낸드 플래시 업계 경쟁사인 하이닉스, 도시바, 마이크론 등도 3D V-NAND 제품을 선보일 예정이기 때문에 2015년부터 낸드 플래시 시장 경쟁도 한층 더 가열될 것으로 전망되고 있다.















